

1. Introduction
Sound change is premised on the inherently variable nature of phonological and phonetic phenomena. The principles of inherent variability and ordered heterogeneity (Weinreich et al., 1968), which hold that socially stratified variation is systemic to language in quantifiable ways, require researchers to consider an array of social and linguistic factors to determine whether a variable feature represents a case of stable sociolinguistic variation or a change in progress. One such variable phonetic feature reported in a number of Spanish dialects is palatal /ʝ̞/ strengthening (Zampaulo, 2019). This occurs when speakers produce the sound written as <ll> in a word like calle (‘street’) or <y> in a word like maya (‘Mayan’) as a more articulatorily constricted, phonetically “stronger” affricate or fricative rather than a canonical approximant; we describe this phenomenon in greater phonetic detail in §2 below. Beginning with Moreno Fernández (2004, p. 982), some researchers have suggested that palatal approximant strengthening is a cross-dialectal, internally driven change in progress in dialects where it is found. However, the sociolinguistically representative evidence needed to substantiate this account is largely lacking, meaning the sociolinguistic status of palatal strengthening within and across most Spanish dialects remains unclear. We begin to address this research gap by reporting findings from a corpus-based, variationist study of palatal approximant strengthening in the variety of Spanish spoken in Medellín, Colombia.
Two research goals guide the investigation. The first is to test the hypothesis that palatal approximant strengthening in Medellín Spanish is an ongoing, internally driven sound change in progress from below as opposed to an imported sound change from above (Labov, 2001); in other words, we test the hypothesis that a documented, synchronic process of palatal strengthening is now a diachronic process of palatal fortition in this variety. To achieve this goal, we analyze the relationship between three social factors—age group, speaker sex, and education level—and production of the palatal phone using a socially stratified sample of Medellín Spanish speakers drawn from the PRESEEA Corpus Sociolingüístico de Medellín (González-Rátiva, 2008). The second goal is to explore the effect of four linguistic factors on palatal strengthening in Medellín Spanish and to identify the particular segmental and suprasegmental pathways that are presumably facilitating its spread throughout the linguistic system and the speech community. These factors include prosodic domain, stress location, preceding segment, and following vowel. While researchers have observed the use of phonetically stronger affricate or fricative variants in the Antioquia region where Medellín is located (e.g., Espejo Olaya, 2013; Montes Giraldo, 2000; Peña Arce, 2015), to date there have been no studies concerning the groups of speakers that exhibit higher rates of the strengthened variants in their speech or the linguistic contexts in which strengthened variants are likely to occur.
The report is organized as follows. In Section 2, we present an overview of /ʝ̞/ strengthening in Spanish that covers its main phonological characteristics, phonetic properties, and geographic distribution. We first draw a distinction between the terms “strengthening” and “fortition” and then contrast the well-known, ongoing spread of /ʝ̞/ assibilation (/ʝ̞/ → /ʒ, ʃ/) in Argentinian Spanish with the understudied, more phonetically variable type of /ʝ̞/ strengthening under analysis here. Section 3 summarizes previous historical and dialectological accounts of /ʝ̞/ variation with a focus on the cross dialectal account proposed by Moreno Fernández (2004) and echoed in subsequent research. In Section 4, we describe the categorical, auditory approach that guided data collection, coding and analysis, while in Section 5 we outline the research questions as they relate to the proposed social and linguistic factors and lay out the hypotheses. Sections 6 and 7 present the results and discussion, respectively. The results reveal a social distribution of strengthened /ʝ̞/ that is consistent with a change in apparent time given the available data, and on the basis of this we claim that /ʝ̞/ fortition in Medellín Spanish is a change from below rather than a change from above (Labov, 2001). In Section 8, we conclude the paper by noting the limitations of the study and identifying potential lines of future research.
2. Overview of Spanish /ʝ̞/ strengthening
A large subset of the phonetic variation attested in the world’s languages and the changes this variation might occasion can be broadly divided into two categories, lenition and fortition. Lenition changes occur when a phonetically weaker sound replaces a phonetically stronger sound among members of a speech community, whereas fortition changes entail the inverse of lenition, as a phonetically stronger sound replaces a phonetically weaker one.[1] According to researchers such as Lavoie (2001) and Bybee & Easterday (2019), the distinction between phonetically weaker and stronger variants rests on differences in the magnitude and duration of an articulatory movement during production. Lenition changes like debuccalization of Old Spanish [ʃ] to [x] (e.g., [ˈaʃo] > [ˈaxo] > ajo ‘garlic’) result from a reduction in the magnitude and duration of the articulatory gesture. In contrast, fortition changes like assibilation of Proto-Romance [j] to Proto-Spanish [ʒ] (e.g., [ˈjocu] > [ˈʒuego] > juego ‘game’) involve an increase in magnitude and duration. These differences in magnitude and duration of an articulatory movement loosely correlate with differences in degree of oral constriction, such that lenition and fortition changes mainly encompass a change in manner of articulation (e.g., approximant > fricative), though a concurrent change in place of articulation is also possible (e.g., palatal > palato-alveolar).
In this paper, we frame the hypothesized fortition change occurring in Medellín Spanish as a community-wide shift from a predominantly sonorant realization to a predominantly obstruent realization of the phoneme /ʝ̞/. In phonetic terms, a sonorant is a sound produced when air flows unimpeded through the vocal tract, and an obstruent is a sound produced when the flow of air is obstructed through varying degrees and configurations of vocal tract constriction. The class of sonorant sounds includes vowels, approximants, nasals, and laterals, while the obstruent class includes plosives, fricatives, and affricates. We conceive the change as sonorant > obstruent to capture the extent of the phonetic variability found across speakers of Medellín Spanish, especially as concerns the strengthened forms of /ʝ̞/ discussed below. Although we did not code tokens according to phonetic form, it appears that Medellín speakers have yet to settle on a single obstruent target. Finally, for the purposes of our analysis we follow researchers such as Colantoni (2008, Argentinian Spanish), Figueroa et al. (2013, Chilean Spanish) and Rost Bagudanch (2018, Peninsular Spanish) in assuming that the underlying form of syllable-initial <y, ll> in Medellín Spanish is a palatal approximant, which we transcribe here as /ʝ̞/ (Martínez Celdrán, 2004, 2015). We do so to allow for a more phonetically straightforward account of the strengthening process in Medellín Spanish while not discounting the validity of alternative phonemic proposals that posit an underlying fricative /ʝ/ (e.g., Hualde, 2005; Scarpace et al., 2015), affricate /ɟ͡ʝ/ (e.g., Kochetov & Colantoni, 2011), or stop /ɟ/ (e.g., Morgan, 2010) for other Spanish dialects.
At the phonological level, variation between sonorant and obstruent realizations of syllable-initial <y, ll> is commonly accounted for in allophonic terms (Hualde, 2005; Martínez Celdrán, 2004; Quilis, 1993). A phonetically stronger, more constricted palatal stop [ɟ] or affricate [ɟ͡ʝ] occurs in absolute initial position (1a) or following a nasal or lateral sound (1b) and (1c), and a phonetically weaker approximant occurs elsewhere (2a). However, as will be shown in this paper and as some researchers have observed (e.g., Hualde, 2005, p. 166), the plosive or affricate sounds may also occur between vowels (as in Example 2a).
- Obstruent contexts
a. Ya veo [ɟ͡ʝa βeo]
b. El yerno [elʲ ɟeɾno]
c. Con lluvia [konʲ ɟuβia] - Sonorant context
a. calle [kaʝ̞e]
At the phonetic level, /ʝ̞/ strengthening leads to multiple possible outcomes. Besides the typical approximant realization of the <ll> in Medellín [meðeˈ ʝ̞in] or the <y> in maya [ˈmaʝ̞a], the phonetically stronger variants include a voiced palatal stop [ɟ], a voiced palatal or palato-alveolar affricate ([ɟ͡ʝ], [d͡ʒ]) that may undergo partial devoicing, and a palatal or palato-alveolar fricative ([ʝ], [ʒ], [ʃ]). All of these variants imply a tighter constriction channel than the approximant, while the affricate and fricative variants are also characterized by an increase in turbulent airflow and consequent frication noise. The exact number and phonetic range of strengthened /ʝ̞/ variants appear to differ among dialects, mostly as a function of real phonetic variability but also because of the sometimes divergent categorical frameworks used by researchers when transcribing and classifying observations (Rost Bagudanch, 2013).
The voiced and voiceless palato-alveolar fricatives [ʒ] and [ʃ] are arguably the most dialectally salient of the strengthened variants, as they are readily associated with speakers of Rioplatense (‘River Plate’) Spanish from the Río de la Plata region of Argentina and Uruguay. In Rioplatense Spanish there is no variation between sonorant and obstruent variants; that is, between approximant-like variants with relatively less oral constriction and affricate or fricative variants with greater oral constriction. When a Rioplatense speaker utters the word Medellín, the <ll> is categorically produced as an obstruent palato-alveolar fricative, either [ʒ] or [ʃ] depending on the speaker’s age, socioeconomic background and reported gender (Michnowicz & Planchón, in press; Rohena-Madrazo, 2015).[2] In Spanish linguistics, this phenomenon is known as rehilamiento (‘stridantization’), and we will occasionally use this term in the rest of the report to refer exclusively to the Argentinian context where the change from [ʝ̞] to [ʒ, ʃ] is less phonetically variable than the process of palatal approximant strengthening in Medellín Spanish. Recent studies have documented palatal /ʝ̞/ strengthening to a palato-alveolar fricative in non-Rioplatense varieties of Argentinian Spanish (Colantoni, 2005, 2008; Coronel, 1995; Lang-Rigal, 2015; Sanicky, 2008), representing a clear case of change from above as the change diffuses outward from the Río de la Plata region. The characteristic rehilamiento of Rioplatense Spanish reflects a change that was likely on its way to completion in this variety by the end of the 19th century (Fontanella de Weinberg, 1995). However, the language-internal constraint(s) that originally gave rise to this change are not well studied.
The type of /ʝ̞/ strengthening examined in this paper differs from Argentinian rehilamiento in two ways. First, it is more geographically widespread. Variable /ʝ̞/ strengthening has been attested in Latin American Spanish dialects in Mexico, Puerto Rico, Chile, Paraguay, and Colombia (Peña Arce, 2015; Young, 1977; Zampaulo, 2019). It has also been reported in the Peninsular Spanish dialects of Western Andalusia and Castile and León (Ruiz Martínez, 2003; Scarpace et al., 2015). Second, it appears to exhibit greater phonetic variability. Consider the ongoing diffusion of Argentinian rehilamiento, where the palato-alveolar fricative represents the normative phonetic target for speakers of non-Rioplatense varieties adopting this change from above. Individual speakers might differ in the degree to which their production of <y, ll> is assibilated, with some being more advanced and therefore showing greater assibilation than others. But if there are no ideological or attitudinal obstacles in the way, over time most—if not all—speakers will settle on a similarly assibilated [ʒ] or [ʃ]. In contrast, variable /ʝ̞/ strengthening presents an array of phonetic variants with different places and manners of articulation. For example, strengthened /ʝ̞/ in Medellín encompasses almost all the possible outcomes listed above with an apparent preference for affricate-like realizations such as [ɟ͡ʝ] or [d͡ʒ]. A third noteworthy characteristic of strengthened /ʝ̞/ in Medellín is that it occurs not only in environments understood to favor phonetic strengthening (e.g., word-initially in a stressed syllable before a high vowel, as in yuca, ‘yuca’) but also in those where strengthening would be less expected (e.g., word-internally in an unstressed syllable between two low central vowels, as in malla, ‘screen’). Despite its wide geographic extent and phonetic variability, there is a dearth of quantitative sociolinguistic work focusing specifically on variable /ʝ̞/ strengthening in Latin America apart from the few studies of non-Rioplatense varieties of Argentinian Spanish cited above. This study begins to fill in this research gap, taking as its analytical starting point the cross-dialectal account of /ʝ̞/ strengthening.
3. The cross-dialectal account: Variable /ʝ̞/ strengthening as a change in progress across dialects
Most previous references to or treatments of variable /ʝ̞/ strengthening have come from the fields of historical linguistics and dialectology in connection to a more general phonological phenomenon in Modern Spanish known as yeísmo (literally, ‘yeism’). In its common usage, the term yeísmo denotes a phonological change involving the loss of the palatal lateral /ʎ/—represented orthographically as <ll> (e.g., calló, caballo, llorar)—from the Spanish phonemic inventory. Prior to this loss, the palatal lateral /ʎ/ contrasts with the palatal approximant or fricative /ʝ̞/ (depending on the analysis), the latter represented by the grapheme <y>. Once the merger of /ʎ/ and /ʝ̞/ is complete, all words with <ll> such as calló come to be pronounced with the same [ʝ̞] as words with <y> such as cayó (whence the term yeísmo); that is, calló and cayó become homophonous (calló [kaˈʝ̞o] ≈ cayó [kaˈʝ̞o]). Varieties of Spanish in which the opposition between orthographic <y> and <ll> is maintained are increasingly rare and are defined by distinción (‘distinction’) whereas those in which it has been lost are identified as yeísta (‘yeist’).
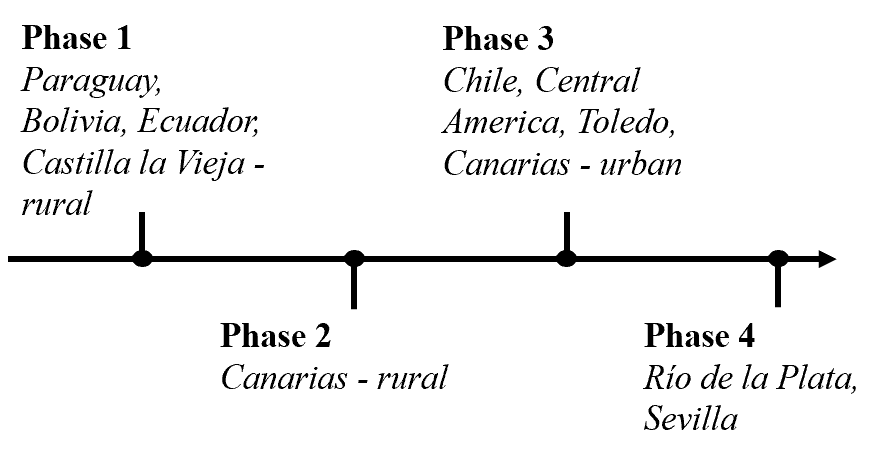
Subsuming variable /ʝ̞/ strengthening under the rubric of yeísmo has led many researchers to view it as the defining characteristic of the penultimate stage in the centuries-long process of change affecting the Spanish palatal phonemes /ʝ̞/ and /ʎ/. We refer to this view of variable /ʝ̞/ strengthening as the cross-dialectal account. According to this account, /ʝ̞/ strengthening represents an internally-driven fortition change in progress in dialects where it is found—with the exception of Argentinian Spanish—but the model does not isolate the phonetic and phonological factors presumed to be acting uniformly across dialects. Moreover, it is teleological in suggesting that this change is heading in the direction of Rioplatense Spanish (i.e. [ʒ] → /ʒ, ʃ/). This view of /ʝ̞/ strengthening is fully formulated in Moreno Fernández (2004), a pivotal work for recent dialectological and sociolinguistic investigations of Spanish yeísmo (e.g., Butragueño, 2013; García Mouton & Molina Martos, 2012; Peña Arce, 2015; Rost Bagudanch, 2013, 2014). Moreno-Fernández (2004, p. 985) proposes a linear model consisting of four historical phases in the evolution of yeísmo:
-
Phase I: Phonological contrast between /ŷ/[3] and /ʎ/
-
Phase II: Merger of /ŷ/ and /ʎ/ in favor of /ŷ/ ; morphological remnants of /ʎ/ (-illo)
-
Phase III: Yeísmo with variable /ŷ/ strengthening or variable /ŷ/ weakening
-
Phase IV: Categorical /ŷ/ → /ʒ, ʃ/
This model allows Spanish dialect zones to be distinguished by Phase. Dialects classified under Phase II are considered less advanced in the evolutionary trajectory of yeísmo, those in Phase III more advanced, and those in Phase IV most advanced. Figure 1 presents a chronological timeline of the four phases together with a representative dialect of each phase as indicated in Moreno Fernández (2004, p. adapted from pp. 986).[4]
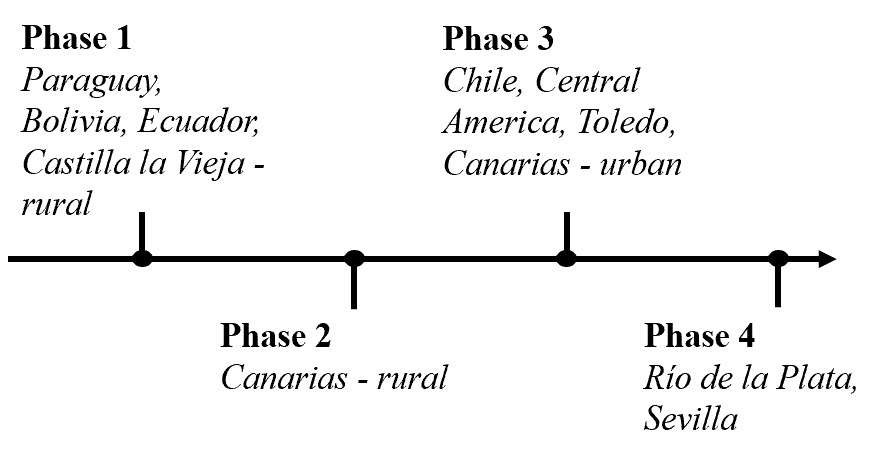
The assumption on which the linear model rests is a central one for traditional dialectology, namely that synchronic variation across space—or geographic variation—reflects change over time (Loporcaro, 2015, p. 14). As Figure 1 suggests, with this assumption in place a variable feature like Spanish /ʝ̞/ strengthening may be accounted for in terms of historical phases of language change, with particular dialect areas representing the postulated phases.
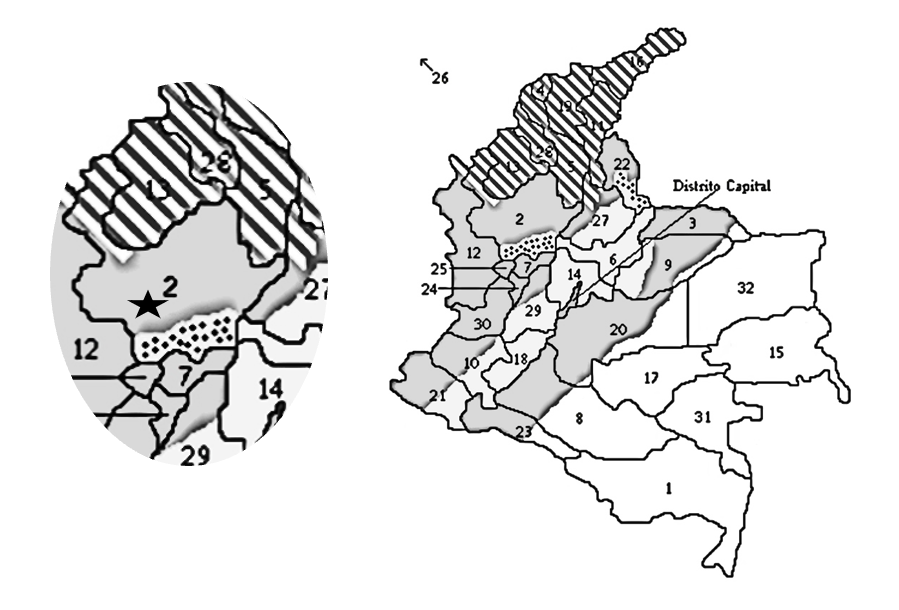
As a unitary entity, Colombian Spanish displays a wide range of yeísmo variation, including both directions of change posited for Phase III (i.e., phonetic strengthening and phonetic weakening). In his overview of yeísmo in Colombian Spanish, Peña Arce (2015, p. 189) frames this variation geographically in Map 1, which is organized with reference to Moreno Fernández (2004)’s linear model. The map draws on impressionistic data originally collected for the Atlas Lingüístico y Etnográfico de Colombia (Floréz et al., 1982).
.png)
In accordance with the methods of traditional dialectology, the map presents differences in the pronunciation of the phoneme transcribed by the author as /ʝ/ in four lexical items: yema (‘yolk’), inyección (‘injection’), gallina (‘hen’) and llave (‘key’). Each phase of the yeísmo model from Moreno Fernández (2004) is identified by a particular shade or pattern. Alternations between shades or patterns are interpreted as isoglossic boundaries separating different phases in the evolution of yeísmo in Colombia. The map shows the department of Antioquia—administrative area ‘2’ —encompassing three separate isoglosses. The city of Medellín—indicated by the black star—is situated within the dark grey area corresponding to Phase III, which is described by Peña Arce (2015, p. 177) as “yeísmo expresado mediante una articulación cerrada palatal, preferentemente [ʝ] o africada [ʤ]” (‘yeísmo realized as a closed palatal, usually [ʝ] or the affricate [ʤ]’). This observation is consistent with previous qualitative reports of yeísmo in Antioquia (Canfield, 1981; Espejo Olaya, 2013; Montes Giraldo, 2000).[5] From the cross-dialectal perspective, these findings suggest that variable /ʝ̞/ strengthening in the speech of Medellín, like variable /ʝ̞/ strengthening in the speech of Toledo, Spain, represents an active fortition change in progress from Phase III to Phase IV.
The cross-dialectal account raises theoretical and empirical issues that this paper seeks to address. It follows from the principles of inherent variability and orderly heterogeneity (Weinreich et al., 1968) that unidimensional variation such as dialect differences cannot constitute the sole basis for plausible inferences regarding sound change in progress. Though dialectal evidence adduced in the form of data from linguistic atlases and anecdotal reports represents an invaluable starting point, arriving at statistically grounded generalizations regarding variation and change requires the use of data gathered from larger, more socially stratified speech corpora. This underscores the need for representative samples of naturalistic speech together with robust, quantitative methods of analysis, both of which have only recently been applied to the study of the multifaceted nature of /ʝ̞/ variation when compared to other, more frequently studied variable phenomena in Spanish (e.g., /s/ and /d/ lenition and deletion). Focusing on Medellín as a starting point, this paper employs variationist methodology to test the cross-dialectal account of variable /ʝ̞/ strengthening as a change in progress.
4. Methodology
4.1. The speech community: Medellín, Colombia
Medellín is the capital city of the department of Antioquia and the second largest city in Colombia with a population of 2,219,861 (Departamento Administrativo Nacional de Estadística, 2005). It is located in the Aburrá Valley in the Western half of Colombian territory. Native residents of Medellín and the surrounding regions are referred to with the term ‘paisa’, a demonym denoting a particular type of regional culture and speech which is widely recognized and acknowledged throughout Colombia. Dialectologists have identified eleven distinct Colombian dialect zones (Bernal et al., 2014). The boundaries of these dialects are represented in Map 2. Medellín is situated in the Antioquia-Caldas dialect zone shown in yellow which, in turn, belongs to a larger, regional ‘Andean’ super-dialect (cf. Montes Giraldo, 1987).
.png)
4.2. Sample
The analysis below relies on a demographically balanced sample of 72 native speakers of Medellín Spanish from the 108-speaker Corpus Sociolingüístico de Medellín (González-Rátiva, 2008). Data were extracted from semi-guided sociolinguistic interviews lasting between 30 minutes and an hour. The interviews deal with a variety of topics related to the personal life of the participants and were conducted in same-gender pairs by fieldworkers who are also native speakers of Medellín Spanish. As mentioned above, in standard Spanish orthography the palatal phoneme /ʝ̞/ is represented by one of two graphemes, <y> and <ll>, as in cayo (‘cay’) and malla (‘mesh’). All instances of orthographic <y> and <ll> were extracted from each interview except for inaudible tokens and repetitions, both of which were excluded. The final total of analyzable tokens of variable /ʝ̞/ came to n = 9,372.
4.3. The dependent variable
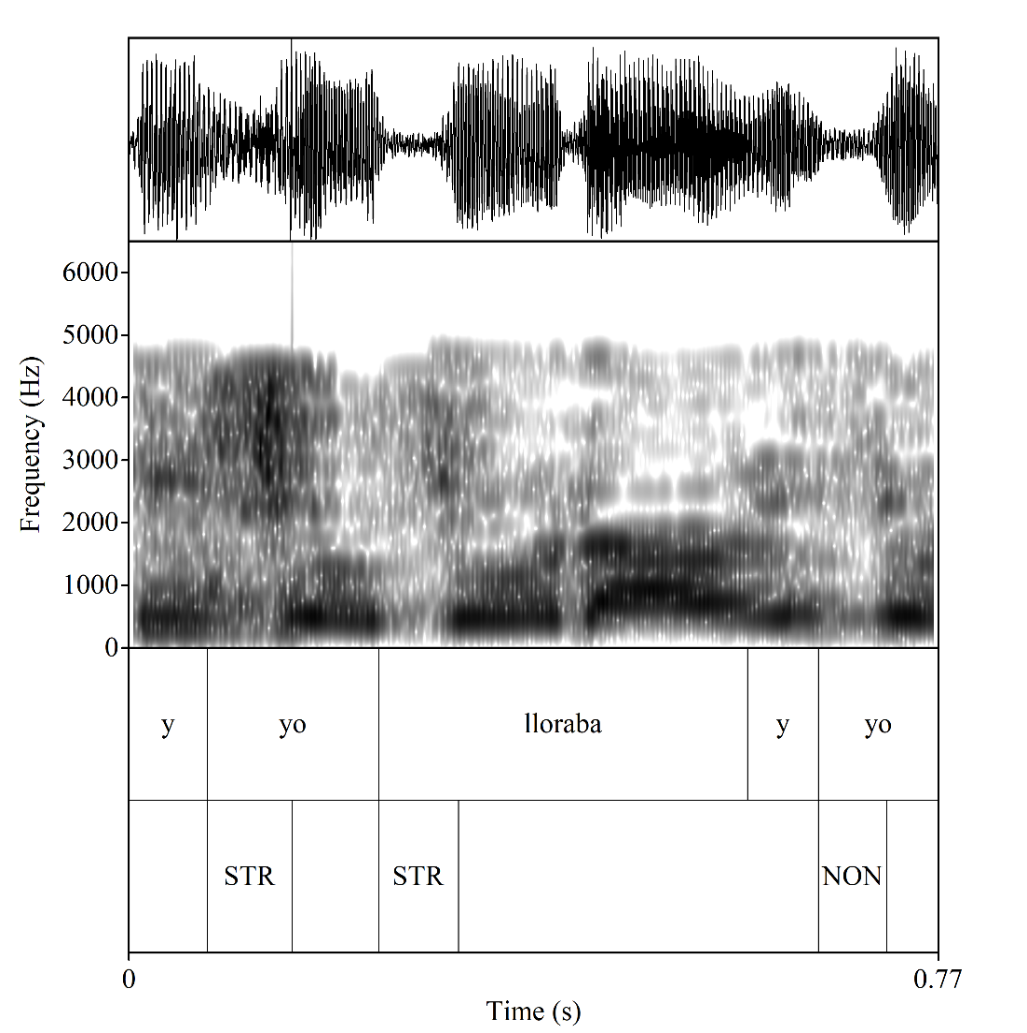
For the purposes of this study, the technique adopted for categorizing individual observations of the dependent variable was auditory phonetic transcription. This was deemed necessary due to the relatively low audio quality of the interview recordings, which precludes a more fine-grained acoustic analysis. All instances of the segment /ʝ̞/ were identified auditorily by the first author as one of two outcomes, closer to non-strengthened, sonorant [ʝ̞] or closer to strengthened /ʝ̞/ ([ɟ], [͡ɟʝ], [ʤ], [ʒ]). Tokens perceived to be produced with virtually no strengthening (i.e., little to no constriction or audible/visible high frequency energy) were considered closer to [ʝ̞] and coded as non-strengthened (NON), whereas tokens perceived to be produced with clear constriction and/or audible and visible high frequency energy were coded as strengthened (STR). This approximate approach to token identification acknowledges that variable phenomena like /ʝ̞/ strengthening tend to exhibit phonetic gradience, in this case from less to greater constriction and frication. Given the gradient nature of variable /ʝ̞/ in Spanish, identifying an individual observation according to discrete, binary categories inevitably oversimplifies the range of phonetic variation present in a large dataset. Therefore, it is empirically more accurate to speak of strengthened variants rather than a single strengthened variant, and we collapse the range of obstruent variants into a single STR category. In this way, the approximate approach to auditory phonetic transcription, though limited in comparison to fine-grained instrumental analysis, attempts to build accountability into the research design. To further improve token identification accuracy and reliability, steps were taken to ensure that any frication noise was maximally perceptible. For each recording, maximum amplitude was normalized, background noise was reduced, and treble levels were increased. All audio processing was performed with Audacity 2.1.0. When necessary, spectrograms and waveforms of individual tokens were visually inspected in Praat (Boersma & Weenink, 2016) to confirm categorization. A sample visualization is given in Figure 2.

The visualization in Figure 2 features three instances of variable /ʝ̞/. The first two instances occur in the words yo (‘I’) and lloraba (‘lloraba’) and were confirmed as belonging to the category ‘STR’ given the visible high frequency noise near the CV transition. The third instance, once again occurring in the word yo, lacks the noticeable high frequency noise of the previous two and was therefore coded as ‘NON’.
4.4. Inter-rater agreement
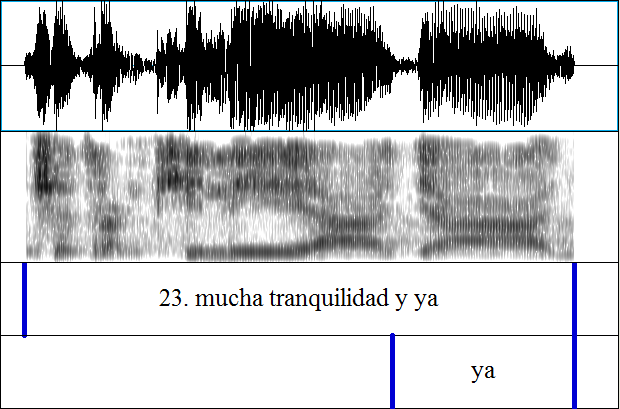
After coding of all included tokens was complete, inter-rater reliability (IRR) was assessed using Cohen’s kappa statistic (Cohen, 1960) and a second coder, a trained phonetician known to the researcher who is familiar with the feature examined here. The second coder was presented with a subset of data from the original dataset. This consisted of two recordings containing the first 170 tokens of variable /ʝ̞/ from two interviews, one with a male speaker, the other with a female speaker (n=340, or 4% of the total data). Each recording was transcribed in two-tiered text grids in Praat, thus affording the second coder the option of visual inspection and replicating as closely as possible the original coding conditions. The coder was instructed to indicate ‘Yes’ for tokens that were ‘more like [ɟ], [͡ɟʝ], [ʤ], [ʒ]’ or ‘No’ for tokens that were ‘more like [ʝ̞]’. A sample Praat transcription with the accompanying spectrogram and waveform is provided in Figure 3.

Cohen’s kappa was then calculated using the irr package in RStudio (RStudio Team, 2020), yielding a kappa value of κ = 0.44. As defined by Hallgren (2012, p. 5), Cohen’s kappa measures “the observed level of agreement between coders for a set of nominal ratings and corrects for agreement that would be expected by chance, providing a standardized index of IRR that can be generalized across studies.” Kappa scores which are closer to 1 indicate perfect agreement, thus closer to 0 indicate random agreement, and those closer to -1 indicate perfect disagreement. According to the interpretation guidelines established by Landis & Koch (1977), a κ value of 0.44 falls within the range of what is considered ‘moderate agreement’. The empirical implications of this value will be returned to in §8.
4.5. Coding schema for fixed effects
To determine whether variable /ʝ̞/ strengthening is a change in progress, we initially coded each token of /ʝ̞/ according to the four social factors pre-determined in the design of the Corpus. These include age group, gender, education level and social class. The factor age group contains four levels: Group 1 (15-19yrs.), Group 2 (20-35yrs), Group 3 (36-55yrs) and Group 4 (56+). The factor education level is categorized into three levels: Primary, Secondary and Post-Secondary. The factor social class also contains three levels: Lower, Middle, Upper-Middle. However, since speakers from an upper-middle class background were underrepresented in the sample (5%), the factor social class was not included in the statistical analysis, leaving only the first three.[6]
All tokens were also coded for four linguistic factors previously shown to constrain the variable production of syllable-initial orthographic <y, ll>. These include word position, preceding segment, following vowel and stress location (Butragueño, 2013; Coronel, 1995; Hualde, 2005; Ohala, 1983; Ruiz Martínez, 2003; Scarpace et al., 2015). The factor levels and examples for each level are provided in Table 1.
5. Research questions and hypotheses
The central research question guiding the analysis presented below relates to the embedding problem in sound change (Weinreich et al., 1968): how does a purported sound change like palatal /ʝ̞/ strengthening pattern in the social matrix of speaker groups that comprise a given speech community? In other words, we ask how the innovative obstruent variants taken together are socially distributed relative to the canonical sonorant variant. The answer to the question underlying the embedding problem is crucial because it allows a variable feature like /ʝ̞/ strengthening in Medellín Spanish to be diagnosed as either a sound change in progress or a case of stable sociolinguistic variation. If strengthened /ʝ̞/ is socially embedded in a way that is consistent with a change in progress, then the next task is to identify the type of change. Sociolinguistic research on sound change often distinguishes two types, changes from above and changes from below. Changes from above occur when an innovative, typically prestige form is imported into the speech community from a different dialect (Labov, 2001, p. 274). The mechanism behind changes from above is contact between dialects or languages. Changes from below occur when an innovative form emerges from the pool of phonetic variation in the speech community (Labov, 2001, p. 31; Ohala, 1989) and conform to a curvilinear pattern according to which female speakers from the middle socioeconomic strata lead the change. The mechanisms behind changes from below are typically language-internal and may include any articulatory factors, acoustic factors, morphophonological factors, and so on (Thomas, 2011). We address the embedding problem in relation to /ʝ̞/ strengthening in Medellín—is /ʝ̞/ strengthening a change in progress, and if so, what type of change—with robust statistical modeling of apparent time data organized by age group. The utility of apparent time data rests on the assumption that an individual’s speech generally reflects the speech of the historical period in which their linguistic system crystallized (Labov, 2001; Wagner, 2012). With these considerations in mind, we make the following predictions for the three social factors Age group, Speaker sex, and Education level:
Hypothesis 1.
If variable /ʝ̞/ strengthening is indeed a change in progress in Medellín, the results should reveal significant differences in use of the strengthened, obstruent variant as a function of age group as well as other social factors. Specifically, it is predicted that the younger the age group, the greater the rate of use of tokens identified as strengthened. We also predict that female speakers will show higher rates of strengthened variant use than male speakers across all age groups, and that speakers with a secondary education will show greater rates of use of the strengthened variant than those with a primary or post-secondary educational background (Bailey et al., 1991; Labov, 2001).
The second issue we address in our analysis relates to the constraints problem in sound change: namely, what are the contextual factors, be they phonological or phonetic, that promote particular pathways of linguistic innovation (Garrett & Johnson, 2013; Weinreich et al., 1968)? To determine the linguistic contexts that favor /ʝ̞/ strengthening, we analyze the conditioning effect of prosodic domain (i.e. position of the sound in the word), stress location, preceding segment, and following vowel, and compare the findings with the relatively few existing studies on Spanish /ʝ̞/ strengthening in other varieties. We make the following predictions for these four factors:
Hypothesis 2.
For the factor prosodic domain, we predict that the overall rate of occurrence of the strengthened variant will be greater word initially than word medially. This is because consonants in word-initial domains are known to undergo more articulatory strengthening than consonants in non-initial domains (Fougeron & Keating, 1997). For the factor stress location, since previous studies suggest that phonetically stronger variants of /ʝ̞/ are favored in stressed syllables as opposed to unstressed syllables, we predict that the overall rate of occurrence of the strengthened variant will be greatest in tonic syllables bearing lexical stress than in pre-tonic or post-tonic syllables that do not bear lexical stress. We also predict that, in line with previous allophonic accounts of /ʝ̞/, coarticulation effects will favor higher rates of strengthened /ʝ̞/ following a consonant and preceding a high vowel.
6. Results
6.1. Social factors conditioning /ʝ̞/ strengthening
The contingency table in Table 2 displays age differentiation in the use of variable /ʝ̞/, offering a first glimpse of /ʝ̞/ strengthening in apparent time.
Three facts emerge from Table 2. First, although the marginal frequency of occurrence of tokens labeled as STR (.34) is lower than that of those labeled NON (.66), it is evident that the production of /ʝ̞/ in Medellín Spanish shows considerable variability. An extremely unbalanced distribution of outcomes would suggest only negligible variability and a lack of meaningful social patterning. Second, the marginal distribution of the two variants is remarkably similar to those found by Coronel (1995, p. 67) in Catamarca, Argentina, a variety which has undergone /ʝ̞/ strengthening under the influence of Rioplatense Spanish (38% strengthened compared to 56% non-strengthened). Finally, the conditional probabilities in the fifth column suggest a modest association between palatal /ʝ̞/ and age group. Younger speakers tend to show a higher probability of use of the strengthened variants compared to older speakers, but we note that this trend is more prominent at the extreme ends of the age scale and much less so for the middle two groups.
To determine whether the magnitude of the apparent age effect in Table 2 was statistically significant in relation to other social factors, a binomial logistic mixed-effects model was fit to the dataset using the lme4 package (Bates et al., 2015) in R Studio (RStudio Team, 2020). Variable selection for the final model used manual backward elimination, a non-algorithmic procedure that begins with a full, complex model and removes one-by-one the predictors under consideration until a null model is arrived at (Agresti, 2007). The complex model included all three social predictors (Age Group+Sex+Education Level) as well as two, two-way interaction terms (Age Group*Sex, Age Group*Education Level). Each model fit in the procedure also specified only by-speaker random intercepts, following Scarpace et al. (2015). Since the first research question relates only to the estimated effect of the social factors on /ʝ̞/ strengthening, the four linguistic predictors were held constant without interaction terms. The goodness of fit for each model was evaluated based on the AIC value rather than p values (Agresti, 2007). The predictors included in the model fit with the lowest AIC value were selected for analysis. Table 3 displays the results of the final model fit (the dashed line separates the social predictors from the linguistic predictors). Neither of the two-way interaction terms were found to be significant nor was education level. All three were consequently excluded from the final model.
The reference level for the intercept in this model is STR. Thus, the coefficient estimates indicate the likelihood of observing a strengthened variant. The positive estimated mean log odds for the fixed-effects intercept indicate that the youngest group of female speakers (15-19) uses the strengthened variants more than non-strengthened variants. Furthermore, the computed p-value (p<.001) shows that the probability of observing a more extreme coefficient estimate for this combination of social factors is very low, meaning the preference for strengthened variants in the speech of the youngest female speaker group is statistically significant. For the second youngest group of female speakers (Age Group:20-35), the mean log odds estimate (-0.51) indicates that the strengthened variants are used less frequently than in the speech of the youngest group, but not by much. The same tendency is seen in the third group of female speakers (Age Group:36-55), although the difference in strengthened /ʝ̞/ use is less than that observed between the two youngest groups. However, the effect for the second and third age groups did not reach the significance threshold (p>.05). The estimated mean log odds for the oldest group of female speakers (56+) is -0.83. This group of speakers thus shows a trend of decreasing use of the strengthened variants that mirrors the trend shown by the previous two age groups. But in contrast to the estimate coefficients from the second and third age groups, the difference between the oldest age group (56+) and the youngest age group (15-19) is considerably greater. The p-value (p<.01) indicates that the difference in the frequency of strengthened variant use between the youngest and oldest age groups of female speakers is statistically significant. Moving on, there is also a large difference in the occurrence of /ʝ̞/ strengthening (-1.20) between males and females of the same age group. That is, the youngest group of male speakers exhibits significantly fewer tokens of strengthened /ʝ̞/ than their female counterparts (p<.001). The apparent-time trends in /ʝ̞/ strengthening as a function of age and gender are visualized together in Figure 4. All figures use the voiced postalveolar affricate as the reference variant for strengthened /ʝ̞/, as this appears to be the most common of the strengthened variants.
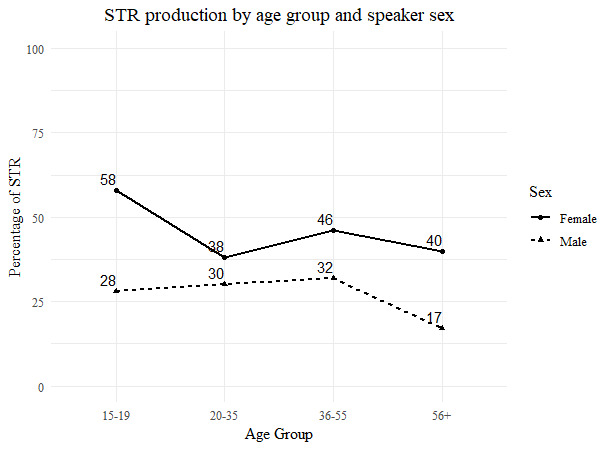
The four age groups are listed on the horizontal axis, while the vertical axis indicates the percentage of strengthened variant use. The solid line indicates the percentage of strengthened /ʝ̞/ production by females, while the dashed line indicated the percentage of strengthened /ʝ̞/ production by males. The line plot shows a clear gender effect across age groups. Female speakers belonging to all four groups show higher rates of use of strengthened, obstruent variants than their male counterparts, even though the differences are not uniform; the gender effect is minimal for the 20-35 age group, whereas it is greatest for the 15-19 age group. The notable spike in strengthened /ʝ̞/ use by the youngest group of female speakers, where the proportion of strengthened observations constitutes over half the total, suggests the change is accelerating in this group. On the other hand, the gradual decline in rates that appears beginning with the third age group of male speakers (36-55) may indicate that these speakers have come to associate palatal /ʝ̞/ strengthening with female speech and, in response, are retreating from or resisting the change. Whether this in fact is the case can only be determined through future perceptual and attitude studies that probe the indexical value(s) of this feature.
6.2. Linguistic factors conditioning /ʝ̞/ strengthening
The variable selection procedure for the linguistic predictors of /ʝ̞/ strengthening was identical to that followed for the social predictors. This time, age group and gender—the two social predictors found to have a significant effect on /ʝ̞/ strengthening—were held constant for all model fits to achieve model parsimony. The final model fit also specified by-item random intercepts. Of the six, two-way interaction terms, only the term for preceding and following vowel was found to improve the goodness of fit. The remaining five were dropped from the final model. Table 4 displays the results of the final model fit for the linguistic predictors. Since the interaction term for preceding and following vowel was not significant, to make interpretation easier the values for the term were excluded from Table 4.
The results presented in Table 4 show a significant effect for only two of the four linguistic predictors included in the model, word position and following vowel. For word position, the estimate coefficients indicate that palatal strengthening is favored in initial position (p<.01), with a moderately strong disfavoring effect for word-medial position (p<.01). Although the factor preceding segment was not statistically significant, the estimate coefficients calculated for each level suggest that postconsonantal context is the most favorable for /ʝ̞/ strengthening, whereas it is least likely after a pause. That strengthening is least likely after a pause contrasts with the findings in Coronel (1995), which presents a variationist analysis of /ʝ̞/ strengthening in the Spanish of Catamarca, Argentina, a non-rioplatense dialect of Argentinian Spanish. In that study, the results of a stepwise regression model revealed a significant favoring effect for /ʝ̞/ strengthening when the segment occurred after a pause. This discrepancy may be due to different transcription criteria: there is no explanation provided in either Coronel (1995) or the Corpus Sociolingüístico de Medellín of how pause was operationalized. Moving on, the results show a marginally significant effect for the linguistic predictor following vowel. The estimate coefficients indicate that /ʝ̞/ strengthening is most likely when the segment precedes a high vowel and least likely before a low vowel. This is consistent with cross-linguistic findings (Ohala, 1983) and those for Coronel (1995). Finally, with regard to the effect of prominence, although /ʝ̞/ strengthening is favored in pre-tonic and tonic position, the differences were not statistically significant.
7. Discussion
With regard to the social factors influencing /ʝ̞/ strengthening in Medellín, the increasing frequency of use in apparent time of the strengthened variants by younger speakers in general and female speakers in particular is consistent with an incipient change in progress. This is the principal finding that addresses the first research question and lends empirical support to the cross-dialectal account of this feature in contemporary Spanish. At this point, we may revisit the question of what type of change is represented by this trend. Variationist sociolinguistic approaches to the study of language change distinguish two types of change, change from above and change from below (Labov, 2001). Change from above occurs exogenously when an innovative, typically prestige form is imported into the speech community (Labov, 2001, p. 274). The mechanism behind changes from above is contact between dialects or languages. Change from below occurs when an innovative form emerges endogenously from the pool of variation in the speech community (Labov, 2001, p. 31; Ohala, 1989). The mechanism behind changes from below is language-internal and may include phonetic factors, morphophonological factors, etc. (Thomas, 2011). The emergence of the postalveolar fricative [ʒ] in non-Rioplatense dialects (Colantoni, 2008; Coronel, 1995) represents a clear example of change from above, as this form is being diffused outward from Buenos Aires, the political and cultural epicenter of Argentinian society. Other examples of change from above include the spread of r-pronunciation in New York City English and the adoption of uvular /r/ in Montreal French (Labov, 2010, p. 185). The second type of change, change from below, begins within the linguistic system—below the level of social awareness—and only later acquires social value (Labov, 2001, p. 279).
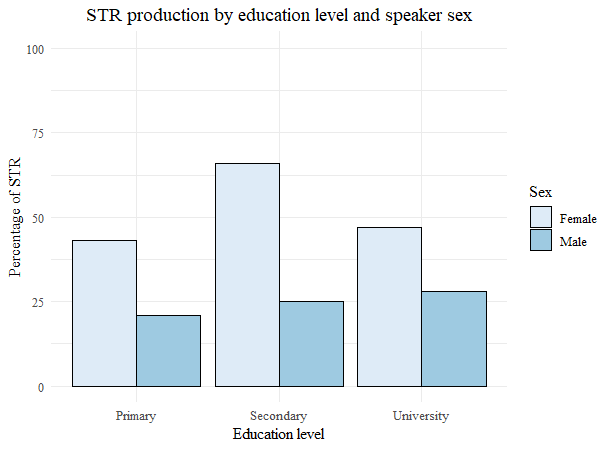
Several social and linguistic trends uncovered in this study suggest that /ʝ̞/ strengthening in Medellín Spanish, in contrast to palatal /ʝ̞/ strengthening in Argentina, is a change from below. The first line of evidence is the higher frequency of use of strengthened variants by female speakers compared to male speakers from all four age groups. This is significant because female speakers tend to lead changes from below, although they may also be the leaders of changes from above (Labov, 1990). A second line of evidence can be found when we examine differences in the frequency of use of strengthened /ʝ̞/ for male and female speakers across educational levels. For changes from below, female speakers tend to surpass male speakers in rates of use of the innovative form at every socioeconomic level (Labov, 2010, p. 197). If the correlation between socioeconomic status and educational level in Medellín is assumed to be moderately strong, then the higher rates of strengthened /ʝ̞/ use by female speakers across educational levels in this corpus conforms to just such an established pattern. The differences in strengthened /ʝ̞/ frequency as a function of speaker sex and educational level are visualized in Figure 5.
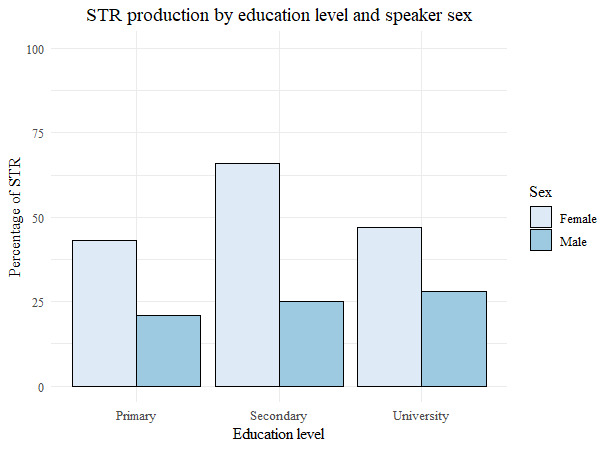
The horizontal axis shows the three education groups determined by the Corpus, while the vertical axis indicates the frequency of strengthened palatal use for male and female speakers. The patterns are similar to those observed for the gender differences in /ʝ̞/ production across age groups. Female speakers across all three education levels show considerably higher frequencies of strengthened /ʝ̞/ use than male speakers, with female speakers from the middle education level exhibiting the highest frequency of strengthened palatal use relative to the neighboring two groups. This pattern follows the curvilinear hypothesis, which “holds that linguistic change from below is led by groups centrally located in the social spectrum” (Labov, 2010, p. 191). If palatal approximant strengthening were a change from above in Medellín, then we would expect to see a more monotonic trend; female speakers from the highest educational group would show the highest rates of strengthened /ʝ̞/ use, with decreasing rates of use associated with lower educational attainment. However, these two social correlates relating to the dataset may not be convincing enough to favor a change from below interpretation of /ʝ̞/ strengthening. Additional evidence supporting such an interpretation can be found when considering language-internal and cross-linguistic tendencies. For instance, it is well known that obstruent allophones of Spanish /ʝ̞/ occur in phrase initial position as well as after nasal and lateral consonants (Hualde, 2005). Furthermore, although glide strengthening is rare cross-linguistically, it has been reported in Swedish, Danish and American English before high vowel monophthongs and diphthongs (Ohala, 1983).[7] Both lines of linguistic evidence align with similar findings presented above for /ʝ/ fortition in Medellín Spanish. Finally, the alternative hypothesis of palatal strengthening in Medellín Spanish as a change from above seems implausible, mainly because there is no viable source dialect from which the strengthened variants might have been imported. Recalling the overview of /ʝ̞/ strengthening in §2, it could be argued that Argentinian Spanish—a dialect of Latin American Spanish and the only variety where the sibilant fricative is the norm—could conceivably serve as a source dialect. However, this would assume sustained contact between speakers of both varieties to allow for diffusion to take place; there is no evidence to suggest that such conditions have ever obtained in and around Medellín. Further research on the subjective and stylistic dimensions of this feature in Medellín Spanish would help to clarify this matter.
With regard to the linguistic factors, it is not surprising to find that /ʝ̞/ strengthening in Medellín Spanish is more likely in word-initial contexts. Consonants in word-initial prosodic domains have been shown to be more susceptible to articulatory strengthening through increased linguopalatal contact than consonants in word-medial or word-final domains (Fougeron & Keating, 1997). Nor is it surprising to find that /ʝ̞/ strengthening is more likely in a tonic syllable—that is, the syllable carrying lexical stress—than in a pre- or post-tonic syllable (i.e., an unstressed syllable). Stress tends to augment the gestures involved in consonant articulation; consonants in stressed syllables are hyperarticulated compared to consonants in unstressed syllables (de Jong, 1995). This finding also echoes the results in two previous studies of /ʝ̞/ variation, Coronel (1995)’s study of rehilamiento in Catamarca, Argentina and Scarpace et al. (2015)’s of /ʝ̞/ allophony in Peninsular Spanish. The results of the mixed-model fit support the initial prediction that /ʝ̞/ strengthening would be more likely before a high vowel, but this finding is at odds with those from Coronel (1995) and Scarpace et al. (2015), both of which showed an effect of the following low vowel /a/. It is not clear whether the source of this discrepancy is rooted in dialect differences or methodological differences, but we intend to explore the effect of vowel-dependent coarticulation in a follow-up acoustic study.
8. Conclusion
This investigation employed quantitative methods and a representative sample of naturalistic speech data to examine the social distribution of strengthened /ʝ̞/ Medellín Spanish. It also sought to shed light on the linguistic constraints conditioning variable /ʝ̞/ strengthening. Multivariate, mixed effects analysis revealed significant differences in the frequency of strengthened /ʝ̞/ use between age groups and between male and female speakers. Both trends strongly suggest that variable /ʝ̞/ strengthening is a fortition change in progress in Medellín with speakers gradually shifting from a sonorant-like to a more obstruent-like realization of /ʝ̞/. In addition, the trend showing female speakers with a secondary education apparently leading the change provides some tentative evidence supporting a change from below interpretation of this change. The analysis also showed that /ʝ̞/ strengthening is favored in word-initial position, in tonic syllables, and before a high vowel, effects which are mostly consistent with those found in previous quantitative studies of /ʝ̞/ variation.
While the evidence presented in this paper supports a view of /ʝ̞/ strengthening as a change from below Medellín Spanish, and therefore also lends support to the cross-dialectal account of /ʝ̞/ strengthening, future research on multiple Latin American and Peninsular dialects is necessary to arrive at empirically reliable conclusions regarding the global status of variable /ʝ̞/ strengthening in Modern Spanish. Additionally, the inter-rater agreement score reported in §5.4, while not indicating a complete lack of agreement about what does and does not represent a strengthened token of /ʝ̞/, underscores the need to utilize fine-grained, acoustic analysis when dealing with gradient phenomena such as the one studied here. Future investigations, which the first author is currently conducting, could consider at least three possible acoustic correlates of palatal /ʝ̞/ strengthening, namely consonant-vowel intensity ratio, harmonics-to-noise ratio, and zero crossings rate, among others. Finally, because the Corpus Sociolingüístico de Medellín only contains speech data from semi-guided sociolinguistic interviews, we were not able to examine the effect of speech style on /ʝ̞/ strengthening. Examining the effect of speech style in relation to a purported sound change aids in ruling out the possibility of age-grading, where individual speakers shift toward different forms of pronunciation over their lifetimes while the community norm remains relatively stable (Wagner, 2012). This limitation will also be addressed in the previously mentioned follow-up study.
Acknowledgments
We would like to thank Jacqueline Toribio, Barbara Bullock, Sandro Sessarego, and the two anonymous HSR reviewers for their helpful feedback and insights. All remaining errors are our own.
Setting aside their common articulatory basis, Bybee and Easterday (2019, pp. 278–279) note that lenition changes typically affect stop consonants, whereas fortition changes typically affect approximants. They write that it is “not entirely appropriate to consider them [lenition and fortition] to be mirror images of each other (p. 279)”.
Rohena-Madrazo (2015, pp. 301–302) did observe the presence of affricate realizations in their corpus of Buenos Aires Spanish, but these only amounted to 6% of the total observations. A very small number of palatal approximant [j] and palatal lateral [ʎ] tokens were also found, with each category representing only 1% of the total observations. Rohena-Madrazo attributes the presence of these “nonnative realizations” to an extreme style shift induced by the word list task used in their study.
Moreno Fernández (2004) employs the phonetic transcription system of the Revista Filológica Española, in which the symbol [ŷ] may refer to an “aproximante palatal sonora fricativizada” (‘fricativized voiced palatal approximant’, [ʝ]) or an “africada palatal sonora” (‘voiced palatal affricate’, [ɟ͡ʝ]) (Rost Bagudanch, 2013, p. 189).
Moreno Fernández (2004, p. 988) is careful to point out that phases may overlap within representative regions, such that vestiges of Phase 1 can be found in areas categorized as Phase 3 while remnants of Phase 3 can be found in areas categorized as Phase 4.
The observation made by Espejo Olaya (2013, p. 231) that “en Antioquia se articula una y rehilada” (‘In Antioquia y is pronounced as a sibilant’) is representative in its brevity and lack of accompanying sociolinguistic information.
In our analysis we view the factor education level as a loose proxy variable for social class. However, we acknowledge that the correlation between the two is far from perfect and take this limitation into consideration in our discussion of the results.
Although the palatal approximant is not a ‘pure’ glide like /j/, it nonetheless exhibits glide-like formant transitions in VCV contexts.