1. Introduction
Descriptively, local gender agreement within nominal constructions in Romance languages like Spanish and Portuguese seems to be a very straightforward phenomenon. Determiners and modifiers need to agree in gender with the noun, such as in (1a), whereas (1b) is ungrammatical because the gender for the adjective and the determiner does not match the gender for the noun.
-
a. El libro blanco
The(Masc) book(Masc) white(Masc)
The white book
b. *La libro blanca
The(Fem) book(Masc) white(Fem)
The white book
In practice, it is well attested that this phenomenon creates persistent problems for L2 speakers, even for those who have achieved a more advanced proficiency level, especially in cases where the L1 does not show such constraints, like English (Bruhn de Garavito & White, 2002; Franceschina, 2001; McCarthy, 2006). Early research on grammatical gender in L2 acquisition focused primarily on whether this feature was acquirable in adulthood if the learner did not possess it in their L1 (Bruhn de Garavito & White, 2002; Franceschina, 2001, 2005; Hawkins, 1998; White et al., 2004), suggesting that the driving factor behind these problems resides in the learner’s syntax failing to enforce local agreement. However, more recent studies examining the acquisition of gender features in L2 Spanish (Alarcón, 2011; Grüter et al., 2012; Kirova & Camacho, 2021; Montrul et al., 2008) and L2 German (Hopp, 2013) by speakers of languages without grammatical gender systematically assert that L2 non-native use of this feature stems from lexical assignment, rather than deficiencies in their syntactic systems.
The Feature Reassembly Hypothesis (Lardiere, 2006, 2009, 2017) asserts that differences between the feature structures of a learner’s L1 and L2 can predict and explain the L2 acquisition path. However, relatively few studies directly compare grammatical gender acquisition in L2 speakers of different L1s (Faber, 2022; White et al., 2004). Likewise, few studies on L2 grammatical gender agreement and assignment employ nonce words to examine the question (Grüter et al., 2012; Ogneva, 2022). To our knowledge there are no studies on the L2 acquisition of grammatical gender that employ nonce words in an oral context to examine the process of assigning gender to a never-before-heard noun.
This study aims to directly compare the performance of L2 speakers whose L1 lacks grammatical gender with that of another group of learners whose L1 not only possesses grammatical gender, but also shows nearly identical morphosyntactic patterns to the target language. We also believe that some interesting data could arise from a direct comparison between behavior of L2 learners in general, and behavior of adult native speakers, when exposed to new words and required to specify the gender features of these novel nouns. In other words, it would be interesting to place the control group in comparable conditions to the L2 groups when learning new words, i.e., without being able to use their previous lexical knowledge in the language as a facilitative tool. In sum, we believe that a three-way comparison between native speakers (NS), L2 learners whose L1 exhibits similar grammatical gender (L2=L1) and L2 learners whose L1 lacks grammatical gender (L2≠L1) could provide further evidence to advance our understanding of this acquisition process, particularly when experimentally manipulating the input to reduce the interference of previous lexical knowledge.
The reasons to provide further experimental data from such direct comparisons become even more evident if we consider some linguistic properties for the distribution of gender values in languages like Spanish. Spanish has two possible gender values for any given noun, colloquially referred to as masculine or feminine. One of the tasks of the language learner, whether it be the L1, L2 or Ln is to assign the appropriate gender to the nouns they learn based on the information in the input. Gagliardi (2012) asserts that noun classes (i.e., grammatical gender) can be characterized using noun-external distributional properties, such as the agreement paradigm and/or using noun-internal distributional properties, which are characteristics of the nouns that make up each class. The external distributional properties in Spanish are seen in the syntactic behavior that exists between nouns and modifying determiners and adjectives, as well as referential pronouns (Corbett, 1991). Internal distributional properties in Spanish include morphological, phonological, and semantic qualities of the noun (Harris, 1991; Kirova, 2016; Kramer, 2015). The canonical and productive gender endings are -o for masculine and -a for feminine, while -e is not strongly correlated with either gender (Teschner & Russell, 1984). Studies show that the morphological form of a word plays a role in gender assignment in young monolingual Spanish-speaking children until roughly age 3 (Hernández Pina, 1984; López Ornat, 1994; Mariscal, 2008; Pérez-Pereira, 1991). In young children, transparent noun endings (-o masculine / -a feminine) are shown to facilitate target gender agreement, whereas deceptive morphology (e.g., el fantasma – “the ghost”) can lead to non-target agreement. Likewise, L2 speakers demonstrate high accuracy rates for gender agreement with nouns that have canonical gender morphology and much lower accuracy rates for nouns ending in -e or deceptively marked nouns, such as la radio (the radio) and la mano (the hand) or el planeta (the planet) and el mapa (the map) (Alarcón, 2010; Montrul et al., 2008).
In addition to noun-internal and noun-external distributive properties, numerous researchers have identified the masculine form as the unmarked gender value (Alemán Bañón & Rothman, 2016; Harris, 1991; Liceras et al., 2008; McCarthy, 2008; Montrul & Potowski, 2007; Valdés Kroff, 2016). Research in early child language acquisition shows children exhibit some overgeneralization of the unmarked (i.e., masculine) forms (Hernández Pina, 1984; López Ornat, 1994; Pérez-Pereira, 1991). Research in L2 acquisition with L1 English speakers suggests that the overgeneralization of the unmarked forms persists even at advanced levels (Bruhn de Garavito & White, 2002; Franceschina, 2001; McCarthy, 2006).
This paper presents experimental data that shows the linguistic behavior of participants from the three groups presented above (NS, L1=L2, L1≠L2) as they ascertain the grammatical gender of nonce nouns presented in Spanish. The L1≠L2 data was collected in the US with English speakers learning Spanish, while the L1=L2 data was collected in Brazil with Portuguese speakers who are learning Spanish[1]. The native speaker data came from participants from different parts of the Spanish-speaking world. In order to guarantee that participants would not previously know any of the target nouns, we used nonce words as explained in section 2.3. As we will see, nonce words also allow us to manipulate the internal distributional properties, following Gagliardi (2012), and to create different conditions to reflect potential mismatches between the syntactic and morphological cues used by speakers to assign gender to novel nouns. The primary goal is to observe to what degree all three groups make use of assignment cues in manipulated morphosyntactic conditions when enforcing agreement constraints using newly acquired lexical items in a production task. Sections 3 and 4 present the methodology used in the study and the results obtained. Such results have implications for L2 acquisition theories, and we briefly describe their potential impact on the current theoretical debate in section 5.
2. Gender, L1, and Nonce Words
2.1. Agreement in Spanish, Portuguese, and English
In assigning grammatical gender to a novel noun in Spanish, speakers can utilize syntactic cues from agreement relations between the noun and its modifiers, morphophonological properties, or semantic characteristics. Of these options, syntactic cues are the most reliable in determining noun gender; nevertheless, even syntactic cues can be uninformative or deceptive. For instance, there are some modifiers, such as possessive determiners and adjectives that end in -e, that do not inflect for gender; thus, it is possible for a noun to be situated in a syntactically ambiguous context, illustrated in (2), where, if the interlocutor is not aware of the noun’s gender, they would not be able to divine it from syntactic cues.
- Mi juguete verde
My(Inv) toy green(Inv)
My green toy
Additionally, dual-gendered nouns present an information mismatch. These are feminine nouns beginning with a tonic /a/ that take a masculine determiner in the singular (3a) but a feminine determiner in the plural (3b); whether singular or plural, adjectives prescriptively agree with the feminine form.
-
a. El águila herida
The(Masc) eagle injured(Fem)
The injured eagleb. Las águilas heridas
The(Fem) eagles injured(Fem)
The injured eagles
Morphological cues are also strong predictors of morphological gender. In Spanish, -o and -a productively mark masculine and feminine gender, respectively, on adjectives, participles, diminutives, and many animate nouns with a semantic gender distinction (e.g., niño/niña ‘boy/girl’, gato/gata ‘male cat/female cat’). Additionally, noun gender is highly predictable from the morphophonological shape of the noun itself. Teschner & Russell (1984) found that 99.9% of nouns ending in -o are masculine and 96.3% of those ending in -a are feminine, thus making -o and -a the most robust morphological indicators for gender. However, there are several other noun endings with strong correlations for one gender or the other. Eddington (2002) found that in addition to -a, the endings -d, -ción, -tis, -sis, and -z are strongly correlated with feminine gender and, in fact, assigning masculine gender to all other noun endings will result in correct gender assignment in 95% of Spanish words.
The most ambiguous noun ending for gender is -e. As we have already seen, adjectives ending in -e are invariable. Likewise, a number of common gender nouns (e.g., estudiante, cómplice, intérprete, rebelde, agente, representante) end in -e. Although the majority of nouns ending in -e are masculine (89%), there are a substantial number of high-frequency nouns ending in -e that are feminine (e.g., leche, sangre, nube, fuente, noche, nieve) (Eddington, 2002; Teschner & Russell, 1984).
Grammatical gender often corresponds to biological gender of animate referents, particularly for humans and domesticated animals (Sera et al., 2002). In both L1 and L2 acquisition, evidence of grammatical gender occurs earlier with animate nouns over inanimate nouns (Alarcón, 2009; Fernández-García, 1999; Hernández Pina, 1984; Montrul et al., 2008). As such, in this paper we will focus exclusively on local agreement between determiners, inanimate nouns, and adjectives, which is mastered by age 3 in monolingual Spanish speakers (Hernández Pina, 1984; López Ornat, 1994; Mariscal, 2008; Pérez-Pereira, 1991), but presents persistent problems for L2 speakers, even at advanced levels (Franceschina, 2005; Grüter et al., 2012; Kirova & Camacho, 2021; Montrul et al., 2008).
Portuguese is typologically similar to Spanish and, when it comes to grammatical gender, it has the same gender distribution. Grammatical gender in Portuguese is a binary system where all nouns are classified as masculine or feminine and this feature produces agreement effects on the same grammatical categories as Spanish (principally determiners, adjectives, quantifiers, and pronouns). As in Spanish, speakers can utilize syntactic, morphological, and semantic cues to assign grammatical gender, and syntactic gender is the most reliable of these cues.
- O livro branco
The(Masc) book(Masc) white(Masc)
The white book
The syntactic constraints on grammatical gender are identical in Spanish and Portuguese; however, determiner-noun agreement in Portuguese provides more reliable gender information than Spanish. Unlike Spanish, possessive determiners inflect for gender (e.g., meu(Masc)/minha(Fem) vs. mi(Inv)); not only does the Portuguese word for ‘one’ (um/uma) inflect for gender, but the word for ‘two’ does as well (dois/duas). Additionally, Portuguese does not have dual-gendered nouns like Spanish (e.g., Spanish el(Masc) águila herida(Fem) in Portuguese is a(Fem) águia ferida(Fem)). This may explain why, in Portuguese, gender is acquired before number in L1 acquisition, whereas in Spanish, number is acquired first (Hooper, 1980).
Morphologically, the masculine and feminine productive markers are the same in Spanish and Portuguese: -o is the productive inflection for masculine forms and -a productively inflects feminine forms (Corrêa & Name, 2003; Rocha, 1981). Moreover, most nouns ending in -o are masculine while those ending in -a are primarily feminine. Corrêa and Name (2003) suggest that since nouns that end in -o and -a have the same morphophonological form as the gender inflections -o and -a, an associative pattern can be established that strengthens the correlation between -o and -a for masculine and feminine, respectively (2003, p. 23). Like Spanish, Portuguese adjectives ending in -e are invariable, as are many common gender nouns (e.g., estudante, cúmplice, intérprete, rebelde, agente, representante).
In both Spanish and Portuguese, the masculine form is considered to be unmarked, which results in gender assignment and processing effects (Beatty-Martínez et al., 2020; Beatty-Martínez & Dussias, 2019; Corrêa & Name, 2003; Harris, 1991; Kramer, 2015; Lawall et al., 2012; Pérez-Pereira, 1991; Rocha, 1981). When it comes to grammatical gender, Spanish and Portuguese have as close to an identical system as two languages can have; the differences reside in the lexical descriptions of individual lexical items.
Unlike Spanish and Portuguese, English lacks grammatical gender. Semantic gender exists with animate nouns which produces referential agreement in the pronominal system, as illustrated in (5).
- The waitressi burned herselfi.
Many nouns referring to people in English are common gender nouns (e.g., agent, assistant, teacher, representative, writer), though some may have significant gender bias (e.g., nurse, secretary, construction worker, firefighter). Animate nouns can also be lexically specified for gender (e.g., woman/man, queen/king, aunt/uncle). Feminine gender may also be expressed morphologically through the suffixes -ess (e.g., actress, goddess, mistress, duchess, lioness) or -ette (e.g., suffragette, bachelorette, dudette). While English does not have grammatical gender, the masculine form has an unmarked quality, like in Spanish and Portuguese. For instance, masculine forms can sometimes be used for female referents, but the reverse is almost never possible.
-
a. The actori saw herselfi in the new commercial.
b. *The actressj saw himselfj in the new commercial.
2.2. L2 Acquisition of Grammatical Gender in Spanish
Grammatical gender has been studied at length in the field of second language acquisition to determine whether features that are not present in a learner’s L1 can be acquired in their L2 later in life. In a spontaneous production study with advanced L1 English learners of French, Hawkins (1998) found that subjects had little difficulty with noun-adjective word order, yet exhibited persistent errors with gender agreement between determiner and noun, which the author concludes is due to the lack of grammatical gender in the participants’ L1.
Noting that Hawkins (1998) only tested a group whose L1 did not have grammatical gender, Bruhn de Garavito and White (2002) and White et al. (2004) examined the acquisition of grammatical gender in Spanish by L1 English and L1 French speakers. The results from these studies indicate that lower-proficiency L2 learners make gender errors at similar rates and that higher-proficiency L2 speakers do not differ significantly from native speaker results, regardless of L1. White et al. (2004) also found that the L1 French speakers were significantly less accurate on lexical items that exhibited a gender difference between the two languages.
Montrul et al. (2008) examined age of acquisition effects on grammatical gender in heritage learners (HL) and L2 Spanish and found that, contrary to the results of White et al. (2004), L2 speakers were highly inaccurate, especially with feminine nouns. They suggest that the difference in findings between their study and White et al. (2004) may be due to the experimental stimuli used. Although White et al. (2004) do not provide a complete list of nouns elicited, the nouns they mention that were used in the study are common, high-frequency nouns: chico, barba, camisa, camiseta, and pantalones. Conversely, Montrul et al. (2008) manipulated 50 nouns divided into canonical, non-canonical, and deceptive endings. They found that L1 English speakers perform very well on gender agreement with nouns that exhibit canonical gender endings, but very poorly with deceptively marked nouns, suggesting that L2 learners’ acquisition of gender is facilitated by noun endings along the following hierarchy:
- canonical → consonant → -e → deceptive
Thus, they suspect that the nouns elicited in the White et al. (2004) study were primarily composed of canonical ending nouns, which would explain why L2 speakers’ performance did not differ significantly from that of the native speakers.
In their parsing-to-learn account, Dekydtspotter and Renaud (2014) suggest that learners of a gendered L2 language, who do not have grammatical gender in their L1, tend to map the properties of their L1 definite determiner to the masculine singular form of the target language definite determiner (the → el in the case of L1 English speakers learning Spanish), as this is the closest counterpart. Thus, when the parser encounters the feminine determiner (la), it works to determine its value in contrast to the masculine form. As the masculine gender is the unmarked form, overgeneralization of masculine modifiers with feminine nouns can potentially be a sign of non-marking (or the absence of gender in the linguistic representation), rather than a clash of feature values.
Grüter et al. (2012) conducted a replication of Montrul et al. (2008) based on the study design of White et al. (2004) and confirmed that advanced proficiency L2 Spanish learners demonstrate native-like performance in offline tasks targeting gender agreement. In this study, Grüter et al. also conducted an online looking-while-listening task, where participants’ eye movements were tracked as they viewed pairs of pictures while listening to sentences that named one of the pictures. Half of the trials contained two items of the same gender (both masculine or both feminine), the other half were mismatched (one masculine, one feminine). The target nouns in these trials included familiar nouns and nonce nouns. Before completing the experimental task, participants were exposed to four novel nouns that were paired with novel objects. They engaged in a total of 20 teaching trials (5 per novel noun) that presented the image of the object with an indefinite determiner (un/una) followed by the target nonce noun. Their results indicate that L2 speakers make use of gender cues in online processing similarly to native speakers with novel nouns; however, L2 learners exhibit weaker use of gender cues with familiar nouns. Grüter et al. suggest that these results can be explained at the level of lexical representation and differences in how infants and adults process lexical information.
In another study employing nonce nouns to explore gender assignment in L2 speakers, Ogneva (2022) presented L2 Spanish (L1 Russian) speakers with nonce nouns that had transparent (-o/-a) or opaque (consonant or -e) endings. Russian, like Spanish, has a grammatical gender system; however, unlike Spanish, its system has three possible classifications: masculine, feminine, and neuter. The results indicate that the L2 speakers assign grammatical gender to bare novel nouns with no distinction from native Spanish speakers, suggesting that the learners have native-like associations between gender and noun morphology.
2.3. Nonce Words
The current study expands the experimental techniques previously used to study this topic by, among other things, employing nonce words presented in context to examine how L1 and L2 Spanish speakers assign noun gender upon exposure to a new word. There are a number of advantages to using nonce words to examine the gender feature in Spanish. First and foremost, a gender feature value has not previously been assigned to these words. This allows the researcher to analyze how these values are assigned to the noun the first time it is encountered based on morphosyntactic and morphophonological information presented in the input, thus shining a light on the productivity of a speaker’s linguistic system.
As Grüter et al. (2012) and Ogneva (2022) have noted, the use of nonce nouns eliminates potential confounds related to the degree of exposure that participants have had to a particular lexical item. As the target nouns have been invented specifically for the purpose of this study, we can state with certainty that none of the participants (native or non-native) have encountered these words before. Likewise, previous studies comparing the gender agreement of L1=L2 speakers have suggested that non-target responses may be the result of confusion between their first and second language (e.g., White et al., 2004). For example, in Spanish, the words for salt and milk are feminine (la sal, la leche), whereas the translation of these words in Portuguese is masculine, despite having the same semantic meaning and very similar phonological forms (o sal, o leite). The implementation of nonce nouns removes confusion from L1 differences as a potential source of non-native production. Moreover, the images and descriptions that identify the nonce words in the current study are designed to avoid any resemblance to already named objects in Spanish, English, and Portuguese (e.g., an image resembling a mask would be avoided because the word máscara is feminine in both Spanish and Portuguese, which could be a potential source of interference in the gender assignment process).
The use of novel nouns in this study makes it possible to standardize test items. For instance, all nouns in the current study are three syllables. Additionally, noun morphology and gender can easily be manipulated to produce the desired conditions (a full description of experimental conditions for the current study is presented in Table 1 of section 3.3). While it is not difficult to find individual nouns that demonstrate the different gender value and morphology combinations (see examples in (8)), finding existing items that illustrate all possible combinations of gender and morphology while maintaining relatively similar frequency, semantic properties, and phonological shape is impossible, demonstrating a clear advantage for the invention of experimental items.
-
Gender value and morphology combinations
a. Transparent masculine: el libro, el suelo, el sueño
b. Transparent feminine: la revista, la silla, la idea
c. Neutral masculine: el puente, el coche, el nombre
d. Neutral feminine: la fuente, la noche, la nube
e. Deceptive masculine: el aroma, el día, el planeta
f. Deceptive feminine: la mano, la radio, la testigo
3. Methodology
3.1. Research Questions
The experimental design of this project creates situations that allow for three gender assignment strategies to be used: (i) morphology; (ii) syntactic relations; and (iii) the unmarked gender value. Though semantic gender can also provide an important cue for establishing morphosyntactic gender in both L1 and L2 speakers (Alarcón, 2009; Pérez-Pereira, 1991), the current study focuses solely on morphosyntactic gender as it is in this domain that Portuguese and Spanish are structurally identical, whereas English lacks this feature completely. This allows us to address the following research questions:
-
Do L2 speakers of Spanish who have the gender feature in their L1 assign its value in the same way as L1 Spanish speakers?
-
Are there similarities in gender assignment strategies that emerge among L2 Spanish speakers, regardless of L1?
3.2. Participants
The current study recruited speakers of Spanish (n = 72) divided evenly into three groups: native speakers (n = 24); intermediate L2 speakers whose L1 is Brazilian Portuguese (n = 24); and an intermediate-high L2-speaker group whose L1 is American English (n = 24). As part of the study, all participants completed linguistic background questionnaires.
Native Spanish (NS) speakers were recruited from a short stay in the United States for a professional development series. Participants, of which 13 identified as men and 11 as women, ranged in age from 19 to 52 years (mean age 30 years). All speakers identified Spanish as their first and dominant language and were raised and educated in Spanish in Latin America until adulthood. The countries represented in this group were Mexico, Guatemala, Uruguay, Peru, Argentina, and Paraguay.
Participants from the Brazilian Portuguese group (L1=L2) were comprised of Brazilian university students (men, n = 7; women, n = 17) studying Spanish in the Brazilian states of Rio de Janeiro or Minas Gerais. The group’s age ranged from 20 to 39 years (mean age 26 years). All BP participants identified Portuguese as their first and dominant language and were raised and educated in Brazil. At the time of data collection, all BP participants were enrolled in upper-level Spanish courses at the university level.
American English-speaking participants (L1≠L2) were recruited from a large public university in the Northeastern United States. The men (n = 5) and women (n = 19) in this group were between 18 and 25 years of age (mean age 20 years), identified English as their first and dominant language, and were enrolled in upper-level Spanish courses at the time of data collection.
All L2 participants were given a modified version of the DELE Proficiency Test (Montrul, 2012) and scored between 30 and 45 points on the assessment, which is considered intermediate-level proficiency.
3.3. Nonce Noun Creation and Selection
The nonce nouns for this study were carefully created. All items were developed as three-syllable nouns and followed Spanish phonotactics. Great care was taken to ensure that the nonce words did not end in a phonological combination strongly associated with one gender value or the other beyond the canonical -o/-a endings. For instance, none of the roots for the nonce words end in -m to avoid the ambiguous -ma ending in the transparent feminine and deceptive masculine conditions since approximately 40% of words with this ending are masculine (Teschner & Russell, 1984). Other noun endings that have strong masculine or feminine correlations, such as masculine -aje or feminine -umbre (Teschner & Russell, 1984) were also avoided.
A list of potential nonce words was presented in the neutral form (i.e., ending in -e) to a group of native Spanish speakers who rated each word on a five-point Likert scale for gender (1 = definitely masculine; 5 = definitely feminine). All nonce nouns that were ultimately selected for test items in this study had an average rating that fell between 2.5 and 3.5. Any words that had an average rating outside this range were discarded. The raters were also asked to indicate if they felt that a word strongly resembled a word that already exists in the Spanish lexicon; these words were also discarded.
3.4. Procedure
To draw attention away from the linguistic focus of the experiment, participants were told that the focus of the study was on memory for novel words. Participants listened to a series of short, audio-recorded situations (18 in total) presented in PowerPoint with visual images to support comprehension. In each situation, a nonce word was presented twice, each time accompanied by a determiner and distinguishing adjective, as illustrated in (9). The nonce word appeared at the top of the screen, written as a bare noun to facilitate participant sound parsing. Following each situation, the images disappeared, replaced by a 3-2-1 countdown on the screen. The scene then reappeared without the objects representing the nonce nouns or the written word at the top of the screen; the participant then heard a question related to the location of one of the items, such as in (10), prompting the participant to respond aloud. The design of the study was such that participants had to produce minimally a determiner and an adjective in order to produce a felicitous response.
-
Pilar dejó un taplino rojo en el sofá y luego dejó un taplino amarillo en el suelo. Se usan para mantener el libro abierto. Fíjate en su ubicación.
English translation: Pilar left aMasc redMasc taplino on the sofa and later she left aMasc yellowMasc taplino on the floor. They’re used to hold books open. Pay attention to their location. -
¿Qué estaba en el suelo?
What was on the floor?
Six versions of the experiment were created so that each nonce word was presented in all six of the gender/morphology combinations, but each participant only saw one condition per specific nonce word. The six experimental conditions are presented below in Table 1.
The situations were presented in sets of six. After each set of situations, participants engaged in a description task where they were asked to describe each of the six items that had just been presented. This was done to avoid monotony and maintain the illusion that the task was related to memory so that participants were not focused on the gender and morphology of the test items.
3.5. Data Coding
Responses were considered target if the gender markings produced on the article and adjective were the same as the gender in the experimental stimuli. Non-target responses were coded as (i) misassigned; (ii) ungrammatical; or (iii) avoidance. Responses were designated as misassigned if the gender produced in the response was different from the gender in the experimental stimuli, but there were no conflicting gender values present. Responses were coded as ungrammatical when the determiner and adjective were marked for conflicting gender values (e.g., laFem taplina amarilloMasc). All other responses were coded as avoidance, which included responses such as no recuerdo ‘I don’t remember’, la cosa… ‘the thing…’ or el objeto… ‘the object…’, and the use of a bare noun with a prepositional phrase as the modifier (e.g., taplino de color amarillo ‘taplino of color yellow’), in which the adjective modified the noun ‘color’ rather than the object itself.
4. Results
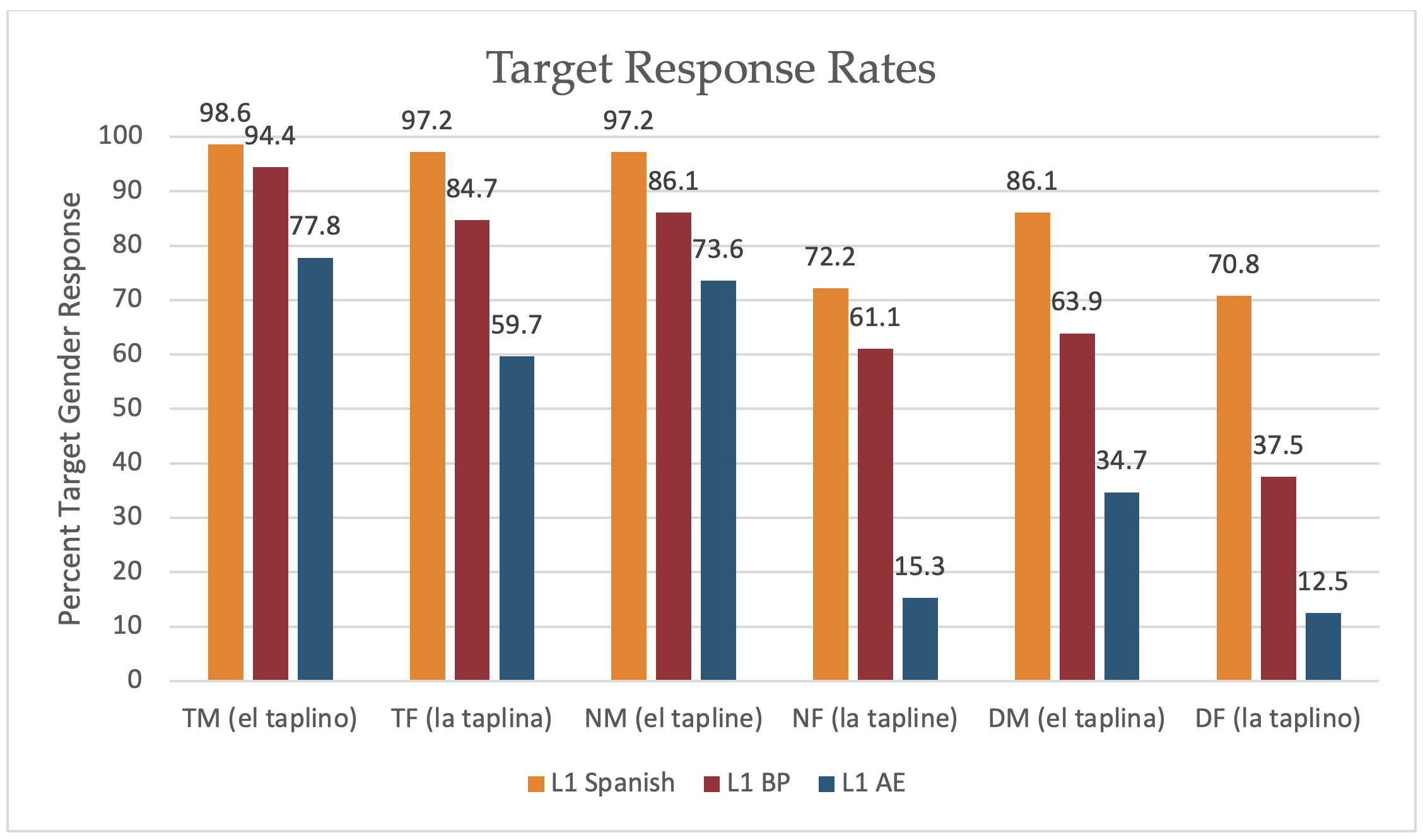
Target gender response rates for all three participant groups (L1 Spanish; L1 BP; L1 English) are presented in Figure 1, reported by condition (Transparent, Neutral, or Deceptive and Masculine or Feminine). Target responses were comprised of at least one gender-inflected modifier in the nominal construction that corresponded to the grammatical gender presented in the stimuli and no elements with a conflicting gender.

All participant groups displayed the highest target response rates in the Transparent and Neutral Masculine conditions, with the Transparent Masculine condition yielding the highest accuracy rates in each of the three participant groups. In the Neutral Feminine and Deceptive conditions, we saw accuracy rates drop across all groups. However, even with the decline in performance, L1 Spanish speakers’ accuracy rates remained well above chance (the lowest accuracy rate, found in the Deceptive Feminine condition, was 70.8%).
Although L1 BP speakers, predictably, did not perform as well as L1 Spanish speakers, their performance followed the same general pattern as the L1 Spanish group in the Transparent and Neutral morphology conditions. However, there was a steep decline in the comparative performance in the Deceptive conditions. As with the L1 Spanish speakers, the L1 BP speakers displayed the lowest accuracy rates in the Deceptive Feminine condition, yet unlike the L1 Spanish speakers, these accuracy rates were well below chance, producing only 37.5% target gender responses.
Among L1 AE speakers, Transparent and Neutral Masculine morphological conditions yielded the highest accuracy rates, just as with the other two groups. However, the overall results suggest that assigning feminine gender was more challenging for L1 AE speakers than for their L1 BP counterparts. Yet, transparent morphology continued to facilitate agreement choices. When feminine nouns were transparently marked (-a), L1 AE speaker accuracy rates were at 59.7%, whereas when the feminine nouns were marked with neutral morphology (-e), accuracy rates plummeted to 15.3%.
The data from all three groups were analyzed using a multiple logistic regression model (Baayen, 2008) in the statistical computing environment R, version 3.1.1 (RStudio Team, 2015). This model was calculated to predict participants’ target responses based on L1 and Condition, as well as their interactions. The established reference levels were set for L1 Spanish for participant group and Transparent Masculine for experimental condition. Error strata were specified to account for individual participant results per condition. No interaction effects were found between L1 and Condition; therefore, a second analysis was performed as a multiple logistic regression without the interaction analysis, the results of which are summarized in Table 2. A Hosmer-Lemeshow goodness of fit test was implemented (χ-squared = 4.9824, df = 8, p = 0.7595), the results of which indicate that our model is a good fit for the data as there was no significant difference between the model and the observed data (p > 0.05).
The results of the logistic regression indicate significance at the 5% threshold for both L2 participants groups as compared to the L1 Spanish speaker group. Additionally, the model yielded significant results for all experimental conditions except for the Neutral Masculine condition. As mentioned above, the reference level for Condition in this analysis was the Transparent Masculine condition, indicating that participants responded to these two conditions similarly.
4.1. L1 Spanish Results
The L1 Spanish speakers attained high accuracy rates for target gender across all conditions, suggesting that they relied most heavily on syntactic cues to assign gender. However, an analysis of participant responses revealed that L1 Spanish speakers were also influenced by the morphophonological shape of the word as well as the unmarkedness of the masculine gender value.
A paired-samples t-test was conducted to compare target gender in each morphological pairing (Transparent, Neutral, Deceptive). No significant results emerged for the transparent morphological conditions, TM and TF, (p = 0.79); nevertheless, significant differences appeared within the neutral, NM and NF, (p < 0.001) and deceptive, DM and DF, (p = 0.0016) morphological conditions.
In an analysis of the masculine value, manipulation of nonce noun morphology yielded the smallest effect among L1 Spanish speakers. No significant difference was found between the Transparent and Neutral Masculine conditions, TM and NM, (p = 0.79), nor between the Neutral and Deceptive Masculine conditions, NM and DM, (p = 0.0641). Significance at the 0.5 level was found between the Transparent and Deceptive Masculine conditions, TM and DM, (p = 0.0345).
The manipulation of nonce morphology produced the greatest effect on target gender assignment with feminine nonce nouns. Statistically significant results emerged between the transparent and neutral conditions, TF and NF, (p < 0.001) as well as between transparent and deceptive conditions, TF and DF, (p < 0.001). However, no significant results were produced between the two non-transparent feminine conditions, NF and DF, (p = 0.79), suggesting that while transparent morphology facilitates target gender assignment, the cost of assigning feminine gender to a non-transparently marked noun is the same, regardless of whether the noun is marked with a neutral -e or deceptively marked with -o.
L1 Spanish responses are summarized in Table 3, categorizing non-target responses into misassigned, ungrammatical with a non-target determiner (*Determiner), ungrammatical with a non-target adjective (*Adjective), and avoidance. Unsurprisingly, nearly all of the non-target gender responses elicited from L1 Spanish speakers were categorized as misassigned; nevertheless, three responses contained an ungrammatical noun phrase. All three of these ungrammatical responses contained a target gender determiner and a non-target gender adjective. While one can argue that these three non-target responses were likely the result of a production error, we argue that production errors stem from a conflict in the representation.
L1 Spanish speakers have a highly productive grammatical gender system where gender is an established feature present on every noun. In the situations to which these speakers were exposed in this study, participants were required to identify the feature values by the cues presented in the input. The gender feature is present and well-established in L1 Spanish speakers’ linguistic system; the task of the speaker is to select the value of that feature. When competing cues are present in the input (e.g., feminine syntactic cues, the unmarked gender default setting, canonically masculine morphology), the speaker experiences a greater cognitive load as they attempt to identify the relevant features in real time, at times to the point of provoking a momentary breakdown in the gender agreement system. However, when all (or most) of the cues point to the same conclusion for gender value (e.g., masculine syntactic cues, the unmarked gender default setting, canonically masculine morphology → masculine), L1 Spanish speakers can assign target gender with relative ease.
4.2. L1 BP Results
L1 Brazilian Portuguese speakers produced target gender agreement at a rate above chance in all conditions except the Deceptive Feminine condition. When we analyzed the paired morphological conditions, we saw a similar pattern emerge as with the L1 Spanish speakers: there was no statistical difference between the transparent conditions, TM and TF, (p = 0.16), but the study yielded significant results for the neutral, NM and NF, (p < 0.001) and deceptive, DM and DF, (p < 0.001) morphological conditions.
In comparing the masculine gender conditions, a paired-samples t-test produced no significant results between the transparent and neutral, TM and NM, (p = 0.23) conditions; however, there were statistically significant differences between the transparent and deceptive, TM and DM, (p < 0.001) conditions as well as between the neutral and deceptive, NM and DM, (p = 0.0013) conditions, which was not statistically significant in the L1 Spanish group.
Among the feminine conditions, paired-samples t-tests yielded significant differences between all feminine morphological conditions: transparent and neutral, TF and NF, (p < 0.001); transparent and deceptive, TF and DF, (p < 0.001); and neutral and deceptive, NF and DF, (p < 0.001).
Table 4 summarizes L1 BP speakers’ responses by type, including a breakdown of non-target gender responses. Whereas L1 Spanish speakers only produced ungrammatical responses in the deceptive conditions, L1 BP speakers produced ungrammatical phrases in all conditions except the Transparent Masculine, with slightly more non-target determiners than adjectives. Additionally, we see that L1 BP speakers employed avoidance strategies, which were not seen in any condition among the L1 Spanish speaker group.
Overall, non-target responses were largely the result of misassignment, rather than a breakdown in the agreement constraints. Just as with the L1 Spanish speakers, target gender assignment was facilitated by congruent gender cues. However, the results from the L1 BP speakers suggest that this group relied more heavily on morphology of the nonce noun in assigning gender than the L1 Spanish speaker group, who did not display differences in gender assignment between the non-transparently marked feminine conditions.
4.3. L1 AE Results
Although L1 American English speakers produced many more non-target gender responses than the other two participant groups, a similar pattern can be seen, in that the Transparent and Neutral Masculine conditions yielded the most target gender responses while accuracy rates dropped in the Neutral Feminine and Deceptive conditions. L1 AE results are compiled by type in Table 5. Here we see that, while the difference between misassigned and ungrammatical responses did not differ greatly in the Transparent Masculine (6 misassigned, 6 ungrammatical), Transparent Feminine (12 misassigned, 15 ungrammatical), and Neutral Masculine (8 misassigned, 6 ungrammatical) conditions, there was a much greater difference between misassigned and ungrammatical responses in the Feminine Neutral (47 misassigned, 11 ungrammatical), Deceptive Masculine (32 misassigned, 11 ungrammatical), and Deceptive Feminine (52 misassigned, 8 ungrammatical) conditions. Of the total solicited responses, more than half (54.4%) were coded as nontarget gender responses. In analyzing the nontarget responses, we find that 66.8% of nontarget responses were misassigned, 24.3% of nontarget responses were ungrammatical, and 8.9% were classified as avoidance.
A series of paired-samples t-tests were employed to analyze the pairs of morphological conditions, the results of which yielded statistically significant differences between all three pairings: Transparent, TM and TF, (p = 0.006); Neutral, NM and NF, (p < 0.001); and Deceptive, DM and DF, (p = 0.002) conditions.
Examining the masculine gender conditions, no statistical results emerged among the transparent and neutral conditions, TM and NM, (p = 0.43). Yet, results for other masculine morphological combinations produced significant differences, both between the transparent and deceptive, TM and DM, (p < 0.001) and the neutral and deceptive, NM and DM, (p < 0.001) conditions. These results are similar to those found in the L1 BP speaker group.
L1 AE speakers differed from the two other groups in the feminine conditions. There was a statistically significant difference between transparent and neutral, TF and NF, (p < 0.001) conditions, as well as between transparent and deceptive, TF and DF, (p < 0.001) conditions. No statistical difference was present, however, between the neutral and deceptive feminine, NF and DF, (p = 0.69) conditions. This is the same statistical pattern that emerged for the L1 Spanish speaker group; yet an important difference exists in these patterns: L2 Spanish speakers’ target gender accuracy rates remained above chance, whereas L1 AE speakers showed no difference between the neutral and deceptive feminine conditions because they were assigning masculine gender in these conditions at very high rates. In fact, if we examine Table 5 closely, the target and misassigned results from the three conditions at the top (TM, TF, and NM) are roughly the inverse results from the three conditions at the bottom (NF, DM, DF). In essence, when the nonce noun ended in -o, L1 AE speakers assigned masculine gender to it at roughly the same rate, regardless of the syntactic cues present. A pairwise t-test comparing TM target responses with DF nontarget responses revealed no statistical significance, (p = 0.778). Likewise, for nonce nouns ending in -a, the results of a pairwise t-test comparing TF target responses and DM nontarget responses yielded no significant results, (p = 0.570). In the neutral morphological conditions, comparing target NM responses and nontarget NF responses, a pairwise t-test revealed a statistically significant result at the 95% confidence level, (p = 0.048).
The results from the L1 AE group are consistent with the findings of Montrul et al. (2008) in that AE speakers’ target gender accuracy is strongly influenced by the morphological shape of the word. When a novel noun ends in a canonical gender vowel (-o or -a), L1 AE speakers generally assign it the gender consistent with the canonical corresponding gender. When a noun ends in -e, L1 AE speakers often default to the unmarked gender value (masculine); however, the results suggest that there may be more inclination to take advantage of the syntactic cues present with neutral morphology as compared to the deceptive morphology in the feminine conditions.
4.4. Non-target nonce noun morphology
As morphology is strongly associated with grammatical gender in Spanish, it is worth examining the cases in which participants altered the target morphology of the nonce noun in their response. Table 6 provides an overview of the number of instances of these shifts per condition for each participant group as well as whether the grammatical gender of the modifiers is target (T), misassigned (M), or ungrammatical (U) with respect to the target item.
Interestingly, though perhaps not surprisingly, we see a similar pattern emerge where the L1 Spanish speakers demonstrated significantly fewer instances of non-target nonce morphology (3.9%) than the L2 groups, with the L1 AE group exhibiting significantly more (11.8%) and the L1 BP group falling in the middle (6.5%). Additionally, the L1 Spanish speaker group only produced non-target morphology on the nonce noun in the Neutral Feminine and Deceptive conditions in a similar pattern to their target gender responses. The non-target morphology displayed by the L1 BP group also seems to follow a similar pattern to the target gender results, with some non-target morphology present in each of the six conditions, and more in the feminine conditions as compared to the masculine. Moreover, the condition with the greatest production of non-target morphology was the Deceptive Feminine condition, which also posed the greatest challenge for L1 BP speakers in the production of target gender assignment and agreement as well. The L1 AE group produced non-target morphology in all conditions as well, though at higher numbers than the L1 BP group.
Among L1 Spanish and L1 BP speakers, non-target nonce morphology occurred primarily among target gender responses. Of course, these groups produced a larger number of target gender responses as well. Nevertheless, the spontaneous changes to nonce noun morphology seemed to occur to bring the noun morphology in line with the grammatical gender. For example, the non-target morphology expressed by the L1 Spanish group in the Neutral Feminine (NF) condition changed the -e ending to -a in the target gender conditions and to -o in the misassigned condition. Likewise, in the Deceptive Feminine (DF) condition, participants changed the -o ending to -a or -e in the target gender responses and to -a in the misassigned response. This was the general pattern among the L1 BP speakers as well.
Although the L1 AE speakers’ non-target morphology production is more extensive, the tendency to regularize or neutralize the noun morphology is the same. In the instances where participants produced non-target morphology in the Transparent Masculine (TM) condition, the misassigned gender responses changed the morphology to be in line with the assigned gender value. For example, where the target response was ‘el quinabro claro’ one participant responded ‘la quinabra clara’ (o → a morphology change), misassigning the gender and producing nonce morphology that is consistent with that assignment.
The production of non-target nonce morphology provides additional evidence of the relationship between morphology and gender assignment when an individual encounters a new word. Furthermore, the results from L1 and L1=L2 speaker groups suggest that an increase in complexity (measured by conflicting gender assignment cues) leads speakers to implement strategies that reduce that complexity, either by assigning gender that is consistent with the nonce morphology or producing nonce morphology that is consistent with the gender agreement cues. L1≠L2 speakers also employ these strategies, though more extensively across all conditions.
5. Possible Theoretical Implications of the Results
As we saw in the results above, the methodology used allowed us to make more nuanced observations about the assignment process for gender features in novel nouns in Spanish, both in the L1 and L2. The overall conclusion might be similar to what is widely known in the field and has been observed in previous studies, i.e., that similar feature configurations within the L1 and L2 have a facilitative effect in the L2 acquisition process. However, this general observation about positive transfer may not capture all the interesting details presented by the data.
Let us consider the participants’ behavior under the Feature Reassembly Hypothesis (Lardiere, 2006, 2009). Stating that English speakers have more problems in acquiring local nominal agreement patterns because they need to add a gender feature to nouns, determiners and adjectives in Spanish does not fully explain why their results, though worse, follow the same pattern as native Spanish and L1 Portuguese speakers for all categories, from transparent masculine to deceptive feminine nouns. The data indicates that all groups are sensitive to markedness, morphology, and syntactic cues; however, the L2 speakers appear to be more sensitive to morphology than the L1 Spanish participants. Moreover, the L1 AE speakers appear to employ morphology and unmarkedness as their primary assignment strategies in this context. These results suggest that L1 and L2 speakers may have different weighting for gender assignment cues that are influenced by morphological transparency, statistical patterns present in the input, and the typological relation between L1 and L2. As we saw in the introduction, several scholars have argued that the difficulty observed with gender agreement in the L2 seems to be better explained by the challenge of lexically specifying the gender value for each noun (Alarcón, 2011; Grüter et al., 2012; Hopp, 2013).
Our results corroborate this hypothesis and allow us to make further claims. Let us remember that the gender assignment process is primarily influenced by three pieces of evidence from the input: (i) syntactic, (ii) morphophonological; and (iii) semantic. Because we are dealing exclusively with inanimate nouns, we do not expect semantic properties to play a key role in gender assignment in our data. As previously seen, transparent morphological cues (-o and -a endings) are a strong predictor of nominal gender in Spanish and Portuguese, though syntactic cues are the most reliable. The data suggest that all three groups have acquired the general morphological pattern for Spanish and use it when assigning gender to novel nouns. Feminine nouns are also more difficult than masculine ones across categories, which indicates that all groups are sensitive to markedness constraints in nominal morphology.
We still need to explain why native speakers can deal with deceptive cases better than L2 speakers in general, and why Portuguese speakers outperform their English-speaking counterparts. For that, we would like to review some facts, and then offer a possible explanation. First, the nature of the task significantly limits the input. Participants are told to focus on the position of the object described by the novel noun, and they only hear two examples for each noun before they are asked to produce it. This does not seem to be enough to assign gender to nouns with conflicting gender values; even for native speakers it poses a significant challenge as they misassigned almost 30% of deceptive feminine nouns. Note that deceptive and neutral cases are the ones in which the participant has to ignore the morphological pattern of Spanish and rely on the syntactic cues in nominal gender assignment. Previous work on L2 processing for grammatical information (i.e., VanPatten, 2007) has argued that learners first process input for content then for form, meaning that semantic information is processed before morphosyntactic information. Since we are dealing exclusively with novel inanimate nouns, there is no semantic information transmitted through nominal agreement. So, we wonder if there is something to be said in an input-intake perspective in SLA (Gass & Mackey, 2007) about the type of morphosyntactic information that needs to be processed to explain why morphological patterns seem to be more easily observable than syntactic ones. One potential claim could be that while processing the input, whenever learners face conflicting or insufficient cues that lead to feature specification, they will rely on well-established (and already acquired) patterns. This, however, does not seem to indicate a specific way in which learners (re)assemble the necessary lexical features in their L2. Given our data, we could speculate that L2 learners, when assigning grammatical features, first process the input from more local to less local information, i.e., features that could be established by morphophonological cues would be assigned first (or more easily) than features whose values depend on information coming from syntactic cues. Although the results presented by this paper seem to indicate this pattern, we would also need to go beyond comparing conflicting cues between morphophonological and local syntactic information to establish this constraint on feature reassembly in different morphosyntactic areas of the grammar. We would need to expand our observations to information coming from local and non-local syntactic constructions. That is why, for the moment, we believe this remains an interesting hypothesis to be further explored.
Regardless of the general claims that can be made about how learners assign feature values, our data support the widely accepted assumption that learners whose L1 shares specific feature configurations with the L2 have the upper hand in SLA. The interesting question in our case is why Portuguese speakers don’t behave exactly like native Spanish speakers since both grammars are exactly the same in this instance and the nonce words are novel words for both groups. This seems to indicate that the direct comparison between feature configuration and specification in L1 and L2 grammars does not present the whole picture when it comes to facilitative learning effects in feature reassembly. Shimanskaya and Leal (2021) came to a similar conclusion in their investigation of L1 Spanish speakers acquisition of singular 3rd person accusative clitics in French. If we again take an input-intake perspective on second language learning, we could argue that there must be other elements in the input that are preventing Portuguese speakers from spending as much of their processing resources on syntactic cues when exposed to the samples used. We are not going to speculate which elements these might be at this point. It suffices to say that Spanish is not Portuguese, and their differences (from phonological to lexical, morphosyntactic, semantic, pragmatic, etc.) do create more demands on Portuguese speakers who are less familiar with elements of the Spanish language. In turn, we could say that transfer cannot simply be explained as a morphosyntactic feature to feature specification, in what sounds like a more theoretically sophisticated contrastive analysis model.
There are surely other elements playing a role in how learners observe and use feature comparisons between their L1 and L2 that cannot be fully explained simply by using a descriptive theory of the interlanguage. White (2007) had already pointed out the limitations of descriptive theories of interlanguage when discussing some misconceptions about generative theories in SLA, saying that a generative theory for language acquisition “does not seek to account for all aspects of L2 acquisition. (…) It is important to understand that UG is a theory of constraints on representation (…). This says nothing about the time course of acquisition (L1 or L2) or about what drives changes to the grammar during language development” (pp. 45-46). One potential way to further develop the Feature Reassembly Hypothesis is to use its theoretical machinery and go beyond questions about what interlanguage looks like according to potential feature bundles and include observations about how these changes in feature specifications might occur.
In sum, whether or not one agrees with the possible theoretical implications that we present in this section, the results of our nonce words experiment provide more nuanced data on how different groups of L2 learners acquire gender agreement in Spanish, and the similarities in the behavior among the two learner groups and the L1 group need to be theoretically explained.
6. Conclusion
By manipulating the morphosyntactic properties of nonce words in a limited input environment, this study presents new data on gender assignment for novel words by Spanish native speakers and L2 learners. Although the comparisons between the three groups corroborated the accepted notion that similar feature configurations between the L1 and L2 produces a facilitative effect in SLA, the similarities among the three groups in relation to feature assignment to nonce nouns present an interesting phenomenon that requires a theoretical explanation. It seems that all three groups use similar cues to complete the gender assignment task, with native speakers being better able to override contradictory syntactic-morphological information when necessary. It is worth noting that this comparison was only possible because we experimentally manipulated the task conditions to place L1 speakers in a comparable situation to L2 learners.
In an era when several researchers are investigating the influence of input in acquisition, one possible next step to the methodology presented here would be to manipulate the amount of input each of our groups would need to yield similar results. Since all groups show similar gender assignment patterns, one can hypothesize that if L2 learners were presented with more input opportunities than L1 speakers, all groups could reach a comparable performance. This would allow us to better understand a potential relationship between the quantity and quality of input in relation to the feature reassembly task faced by the learner. Obviously, this will need to be ascertained by future projects.
We would like to thank our colleagues in Brazil for facilitating data collection in their research labs: Prof. Marcus Maia (UFRJ) and Prof. Raquel Fellet Lawall (UFJF).